Latent Belief Space Motion Planning under Cost, Dynamics, and Intent Uncertainty
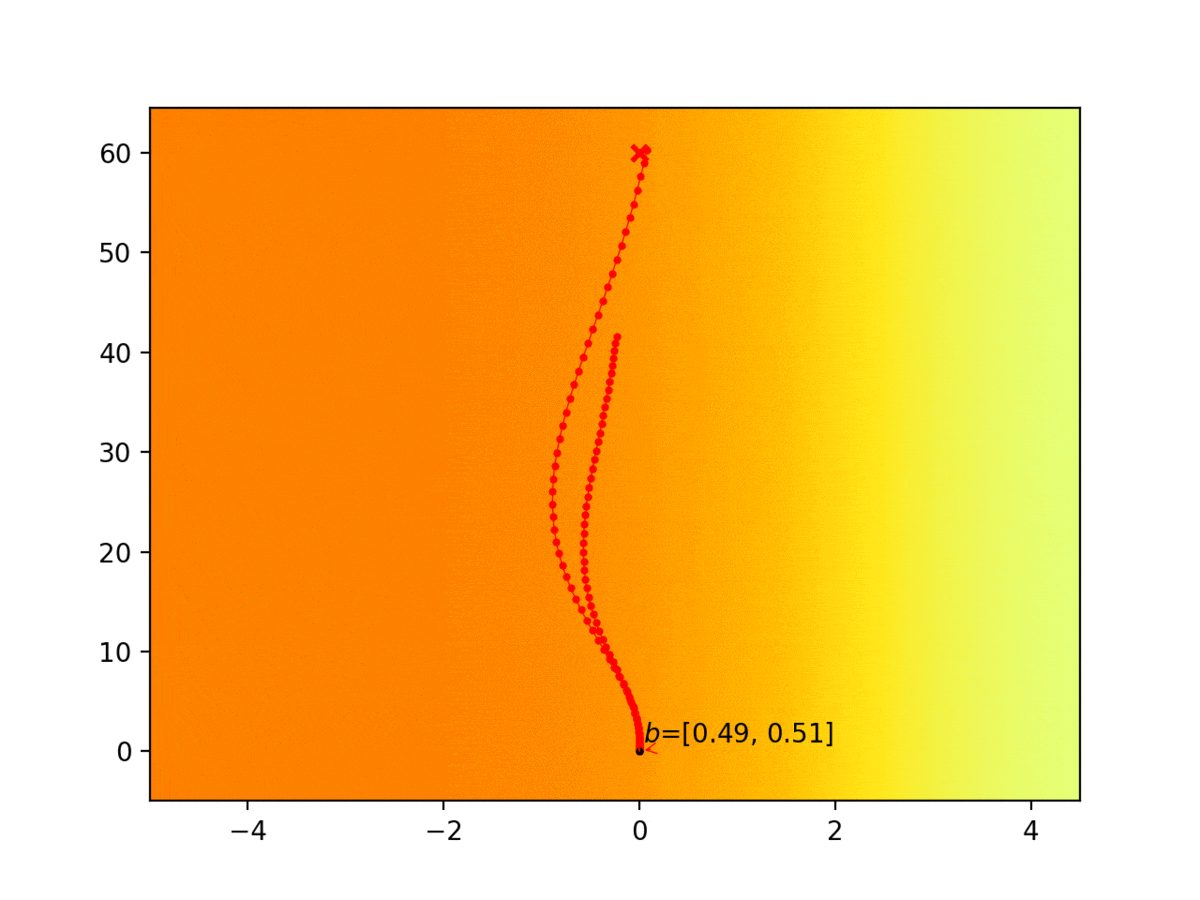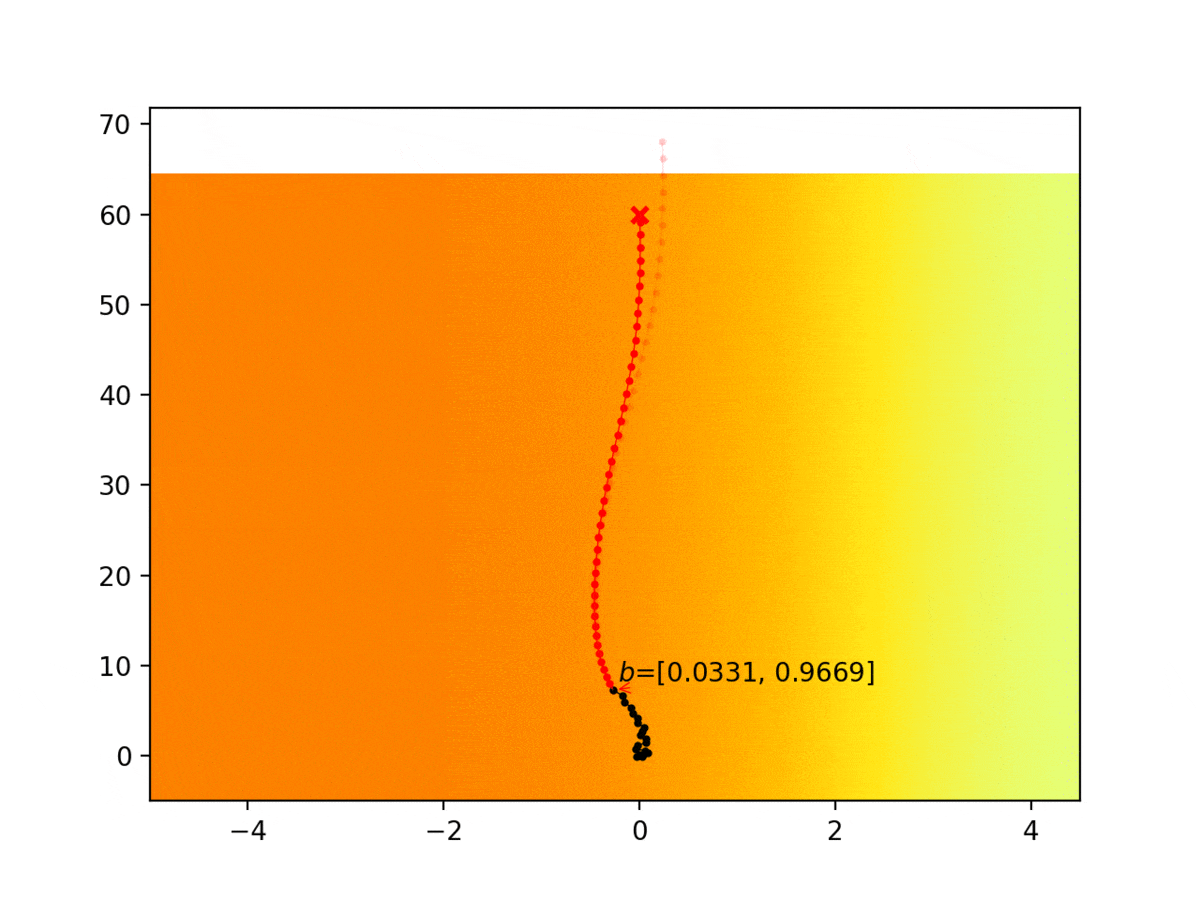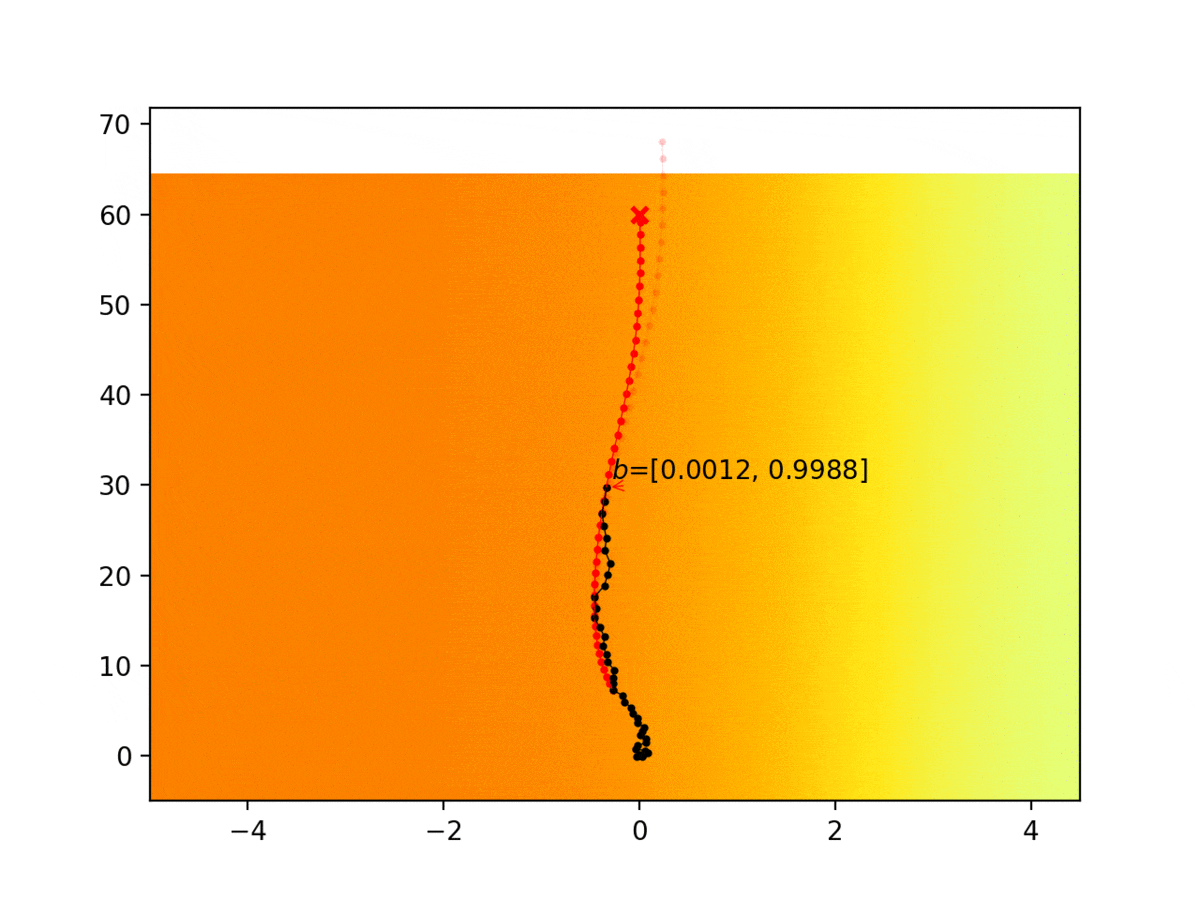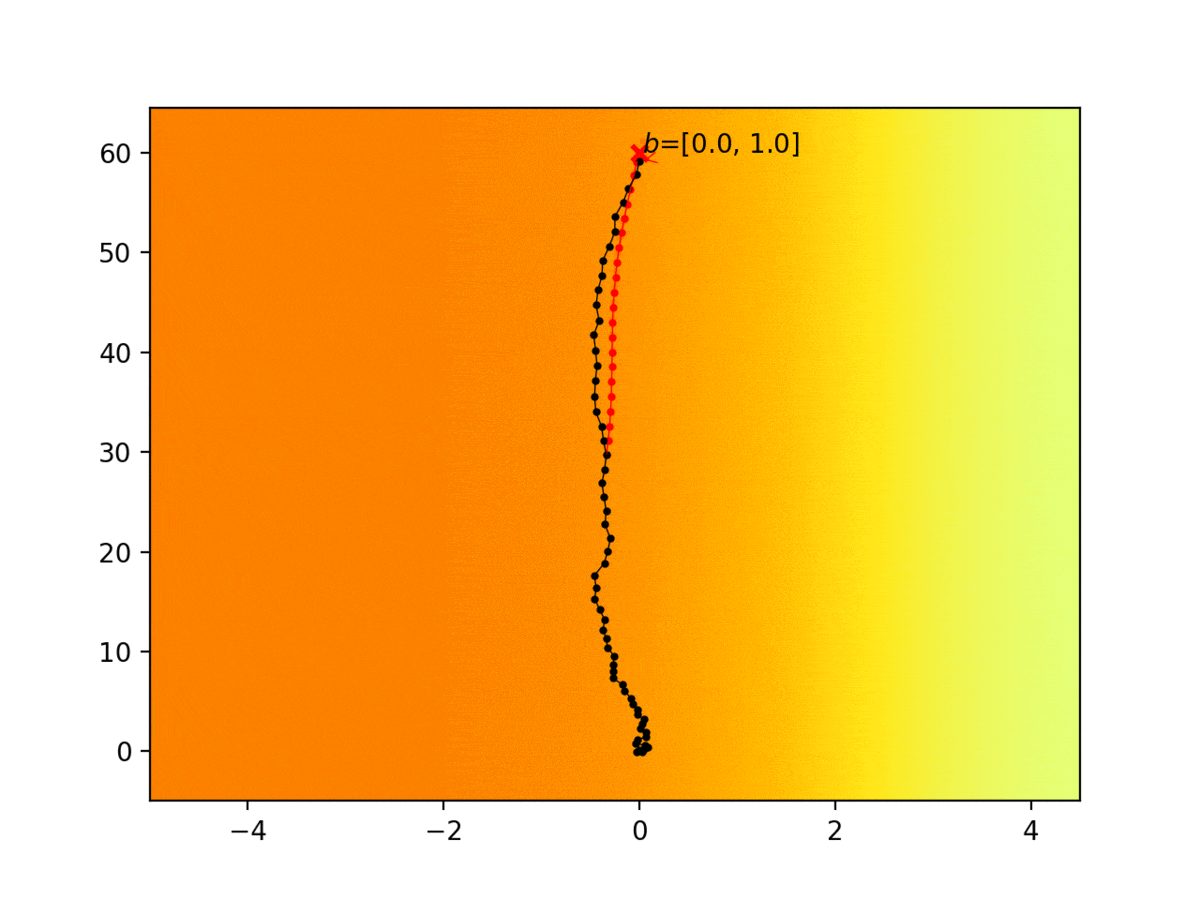
Autonomous agents are limited in their ability to observe the world state. Partially observable Markov decision processes (POMDPs) model planning under world state uncertainty, but POMDPs with multimodal beliefs, continuous actions, and nonlinear dynamics suitable for robotics applications are challenging to solve. We present a dynamic programming algorithm for planning in the belief space over discrete latent states in POMDPs with continuous states, actions, observations, and nonlinear dynamics. Unlike prior belief space motion planning approaches which assume unimodal Gaussian uncertainty, our approach constructs a novel tree-structured representation of possible observations and multimodal belief space trajectories, and optimizes a contingency plan over this structure. We apply our method to problems with uncertainty over the reward or cost function (e.g., the configuration of goals or obstacles), uncertainty over the dynamics, and uncertainty about interactions, where other agents’ behavior is conditioned on latent intentions. Three experiments show that our algorithm outperforms strong baselines for planning under uncertainty, and results from an autonomous lane changing task demonstrate that our algorithm can synthesize robust interactive trajectories.
@INPROCEEDINGS{Qiu-RSS-20,
AUTHOR = {Dicong Qiu AND Yibiao Zhao AND Chris Baker},
TITLE = {Latent Belief Space Motion Planning under Cost, Dynamics, and Intent Uncertainty},
BOOKTITLE = {Proceedings of Robotics: Science and Systems},
YEAR = {2020},
ADDRESS = {Corvalis, Oregon, USA},
MONTH = {July},
DOI = {10.15607/RSS.2020.XVI.069}
}
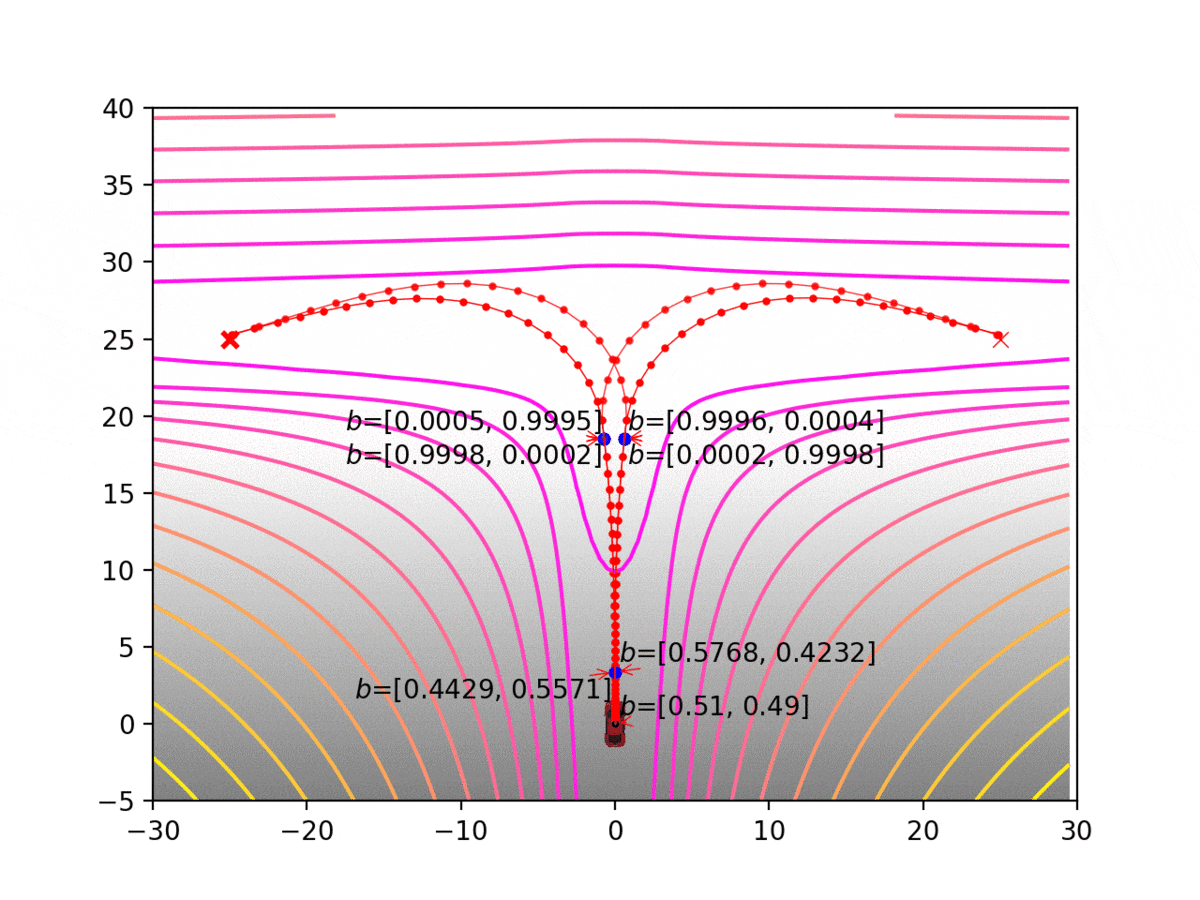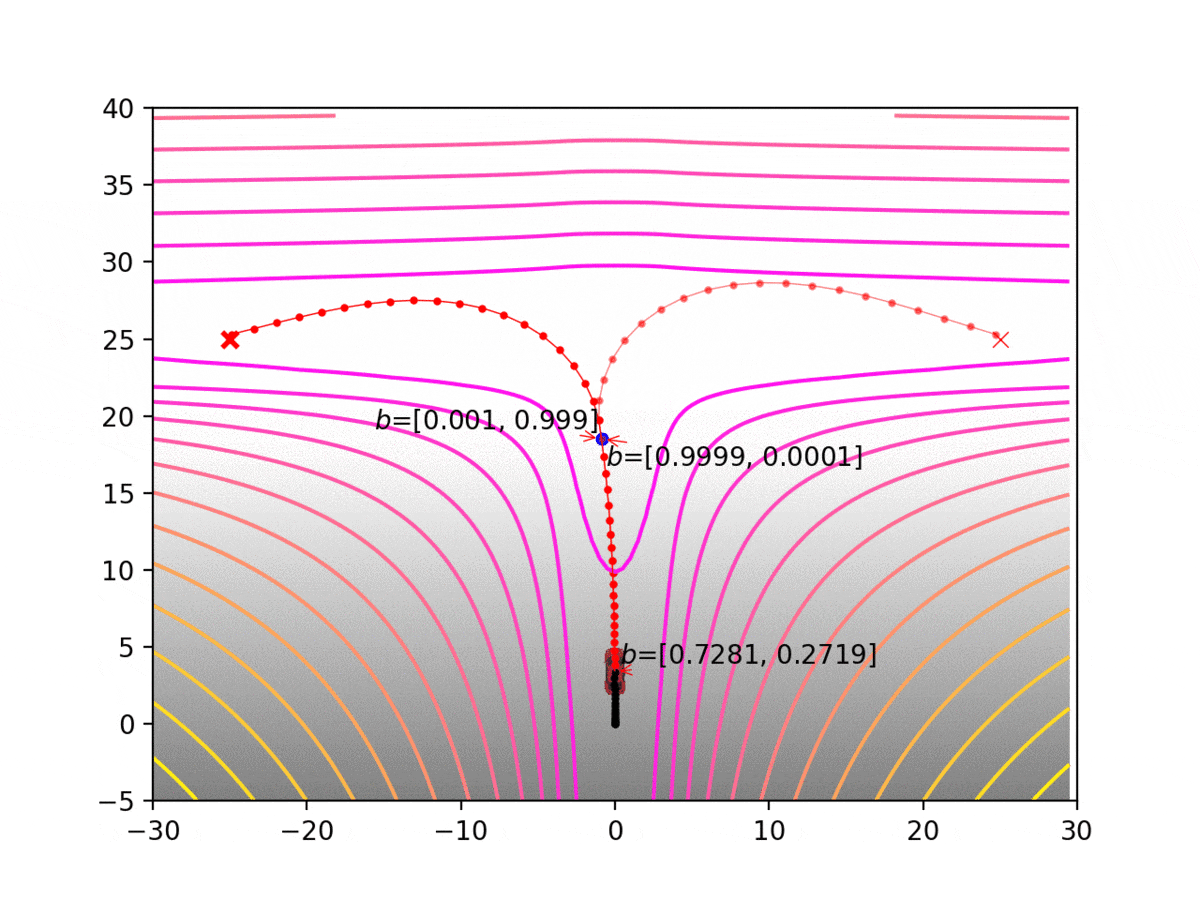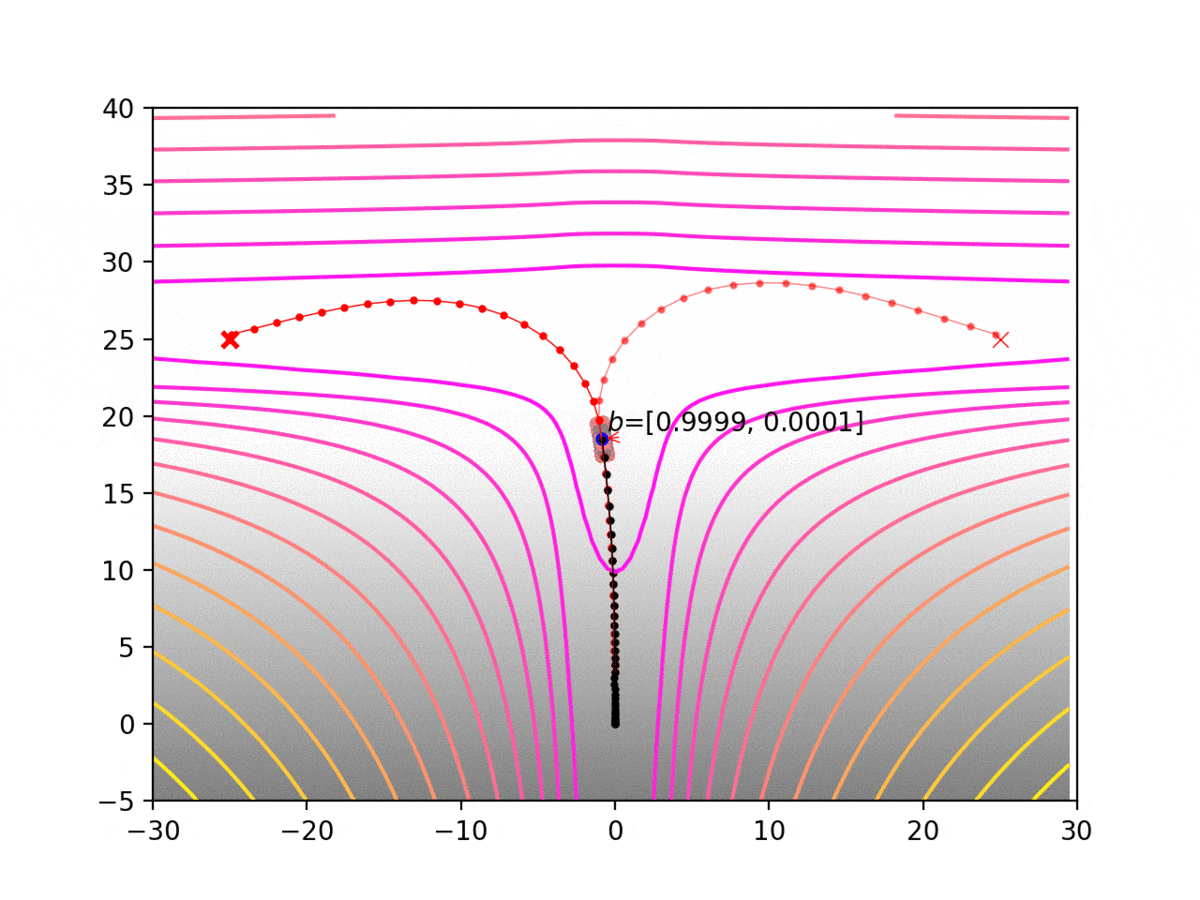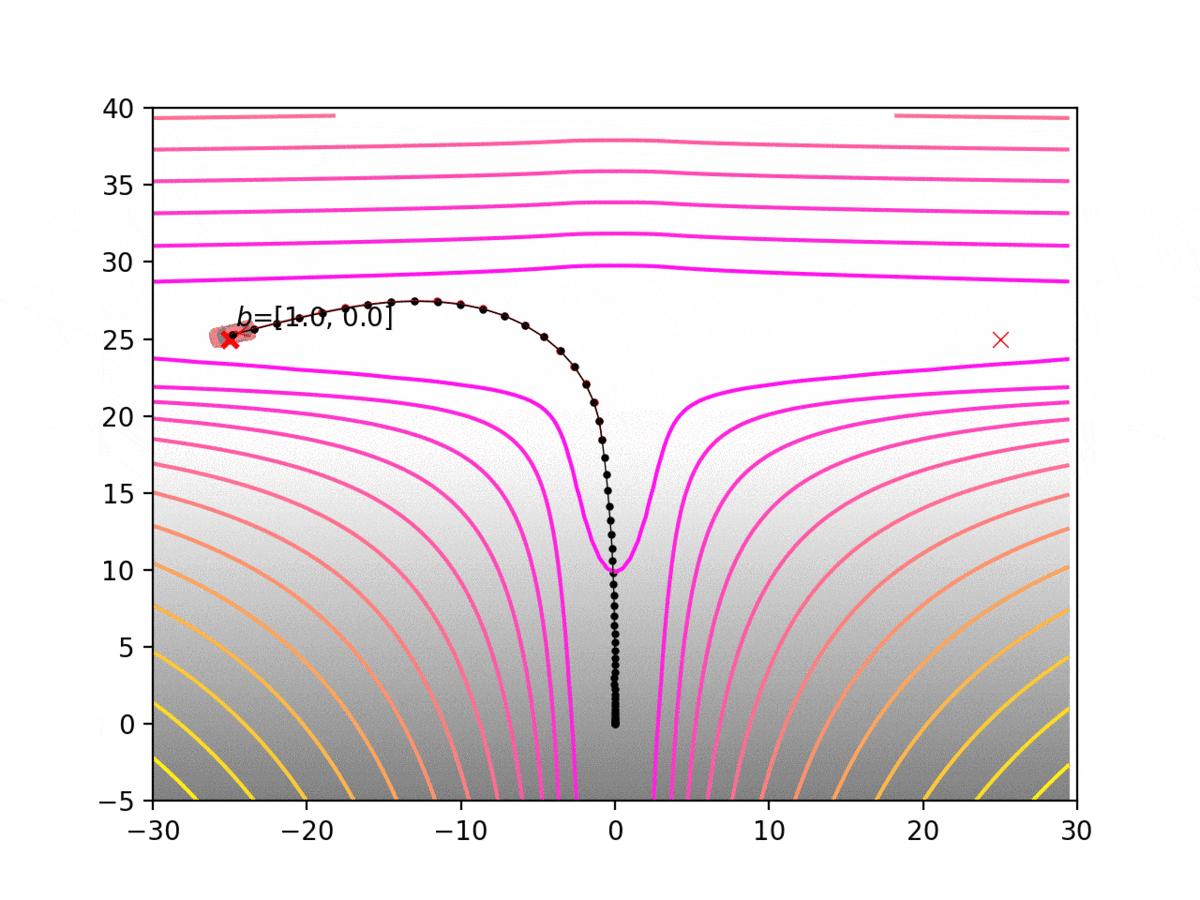
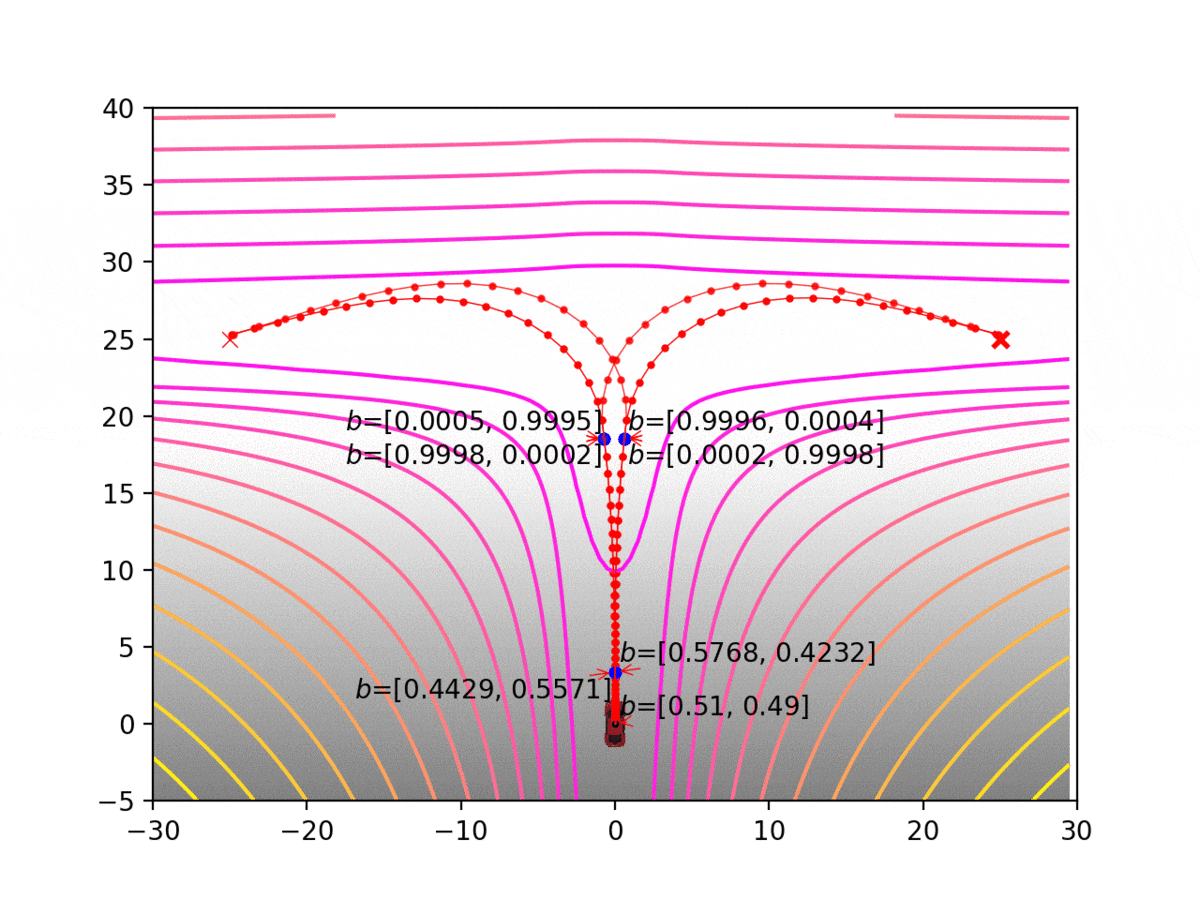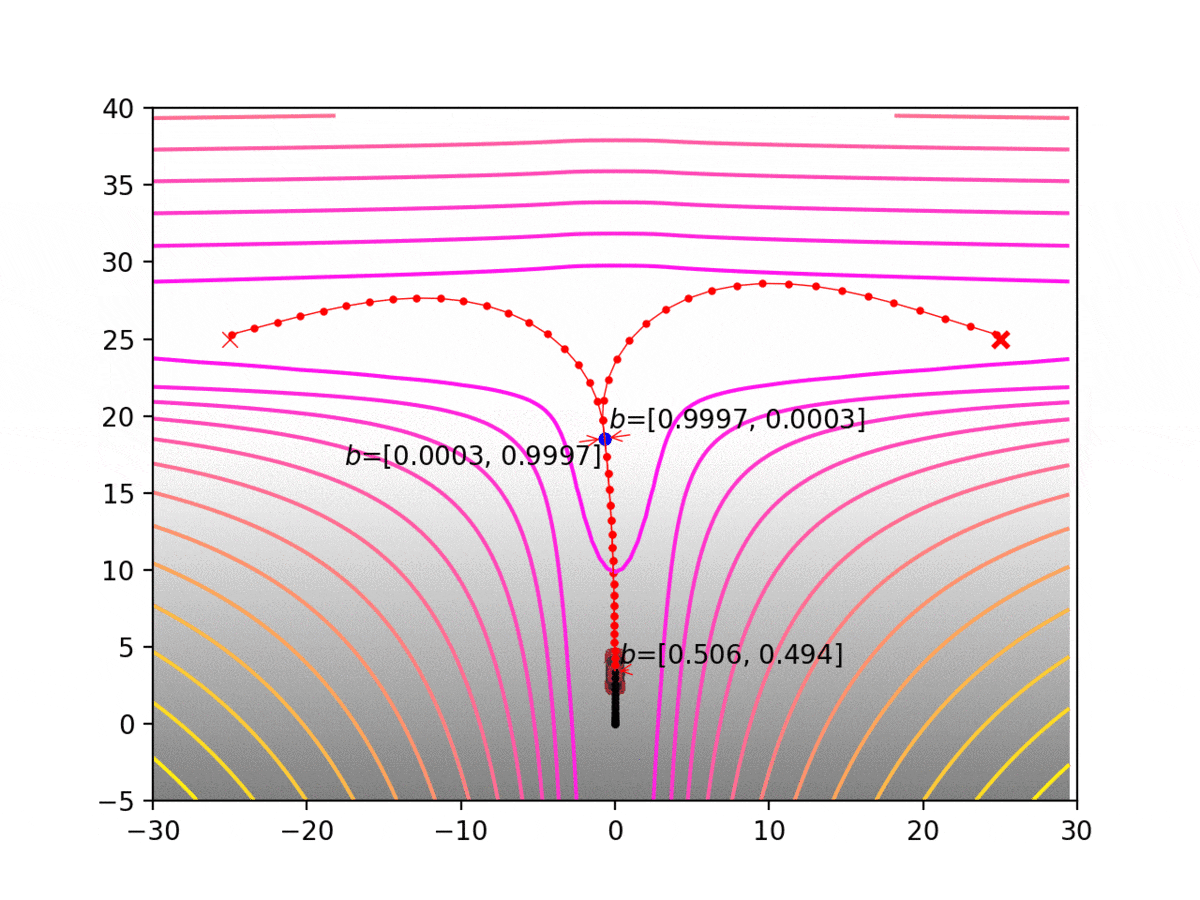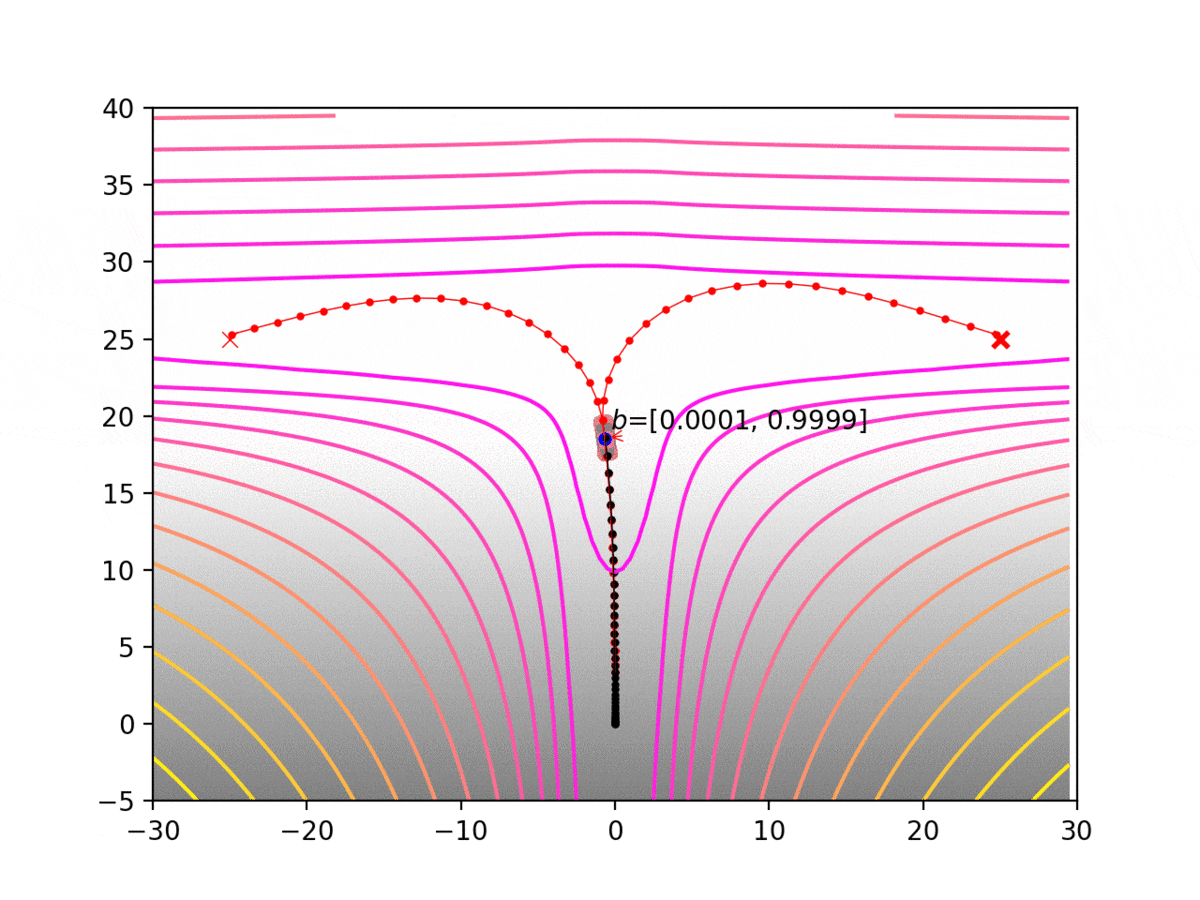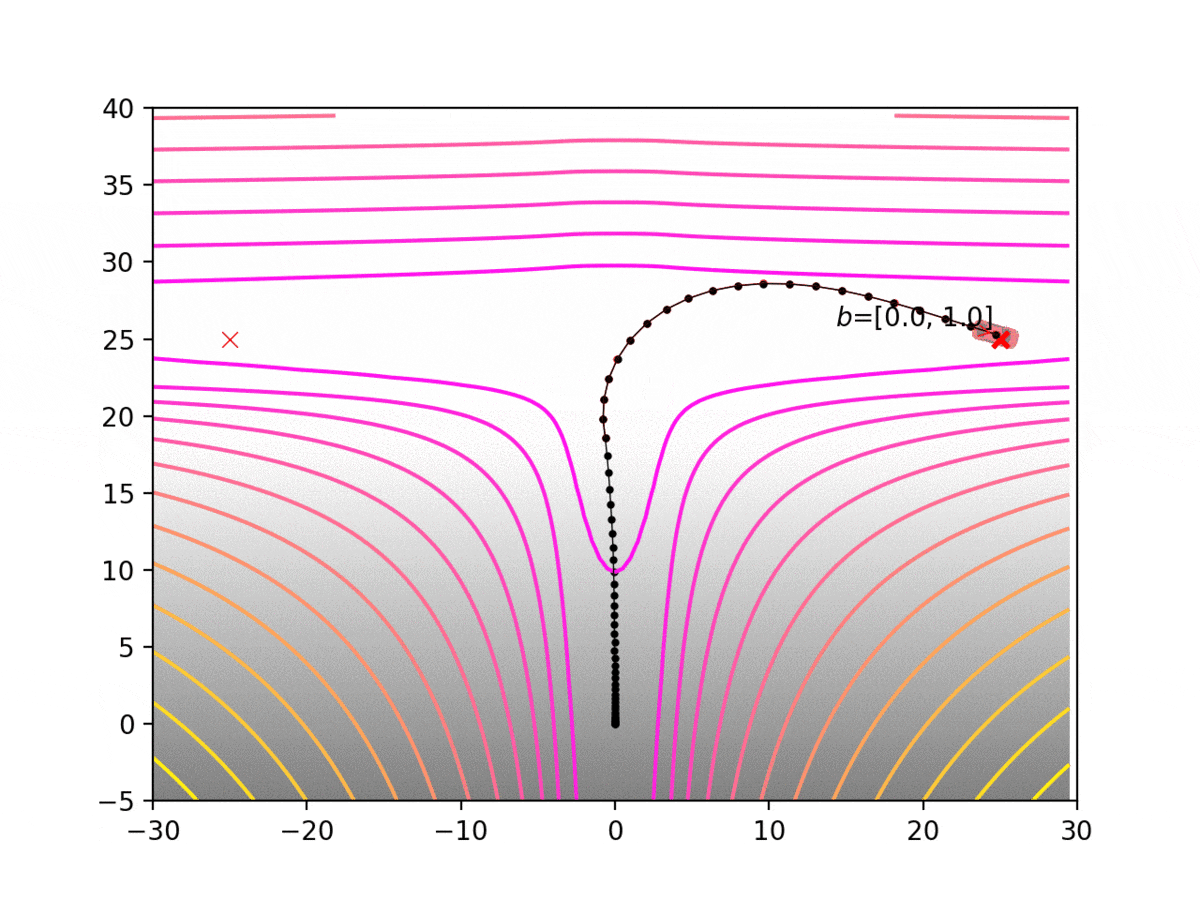
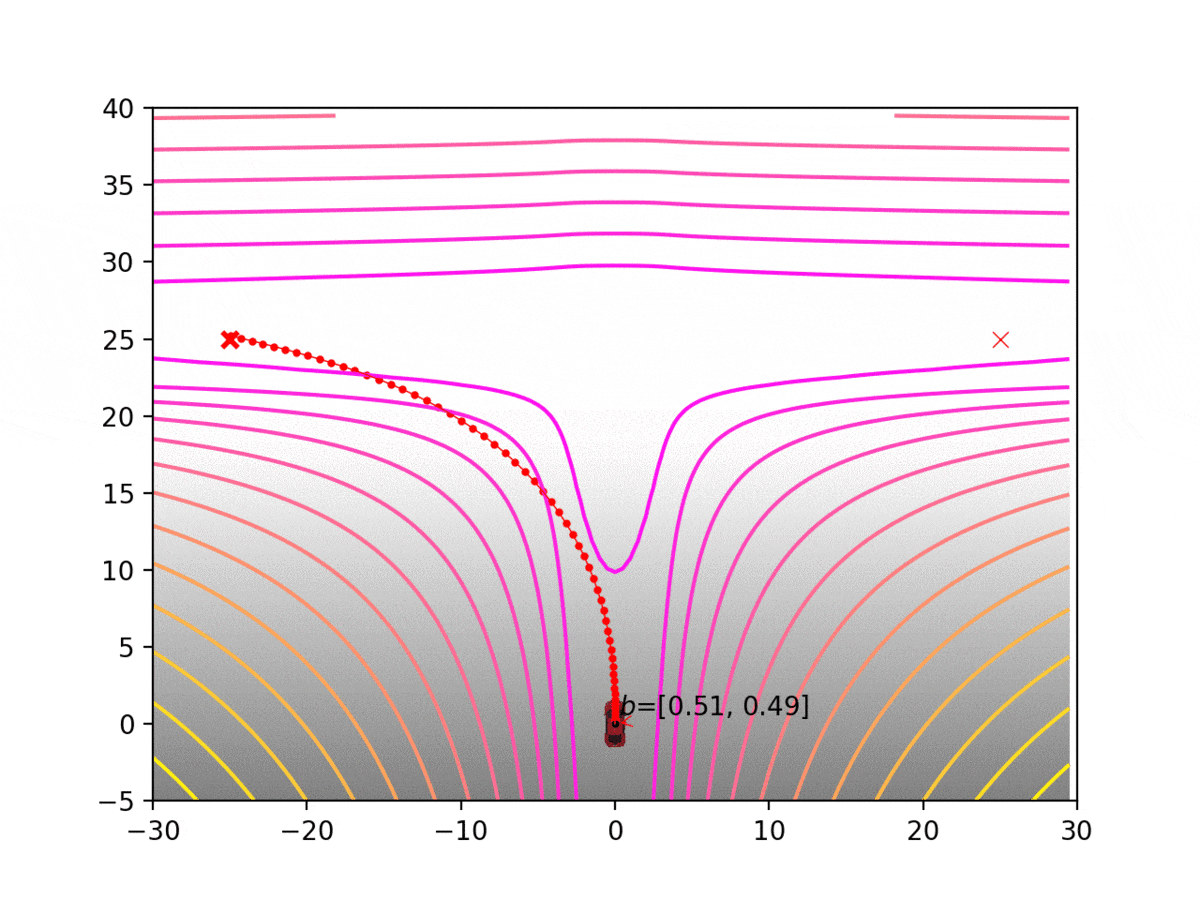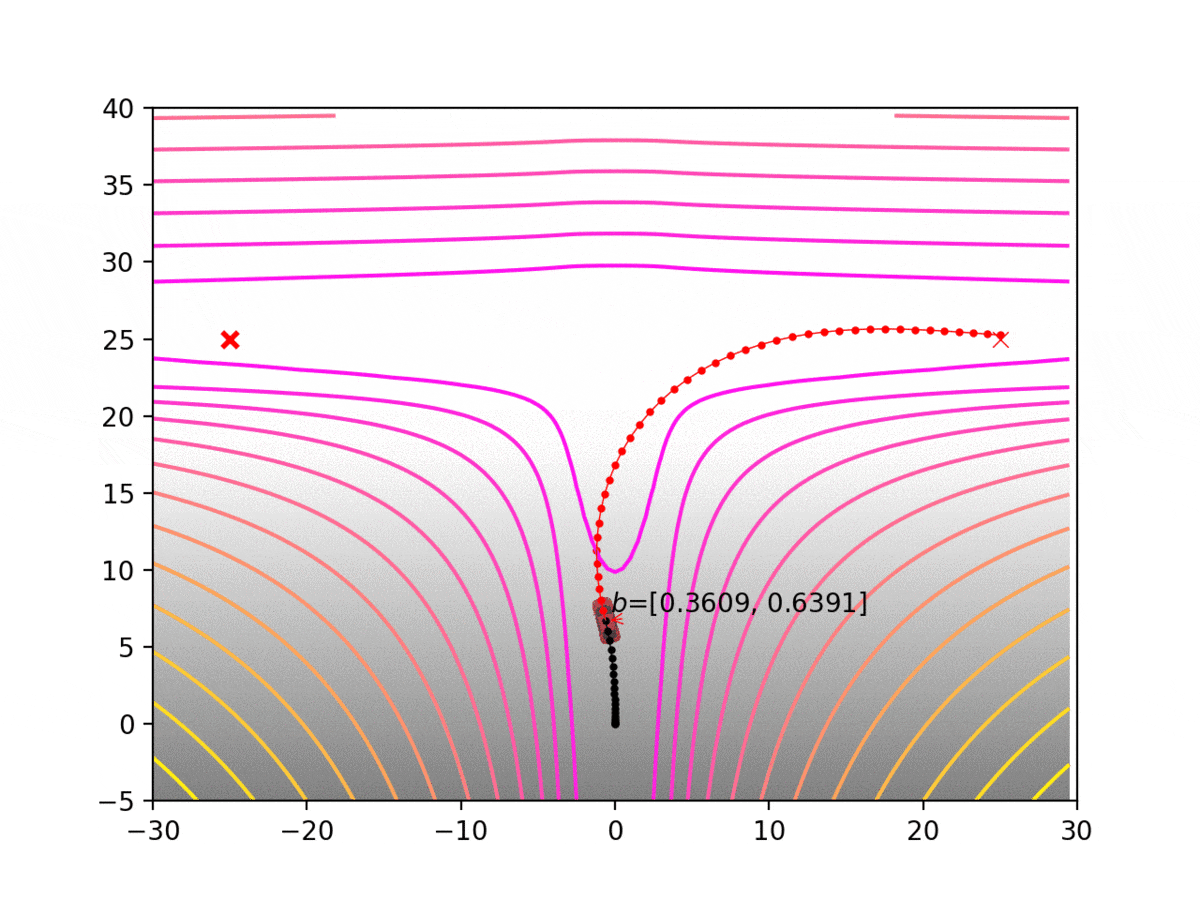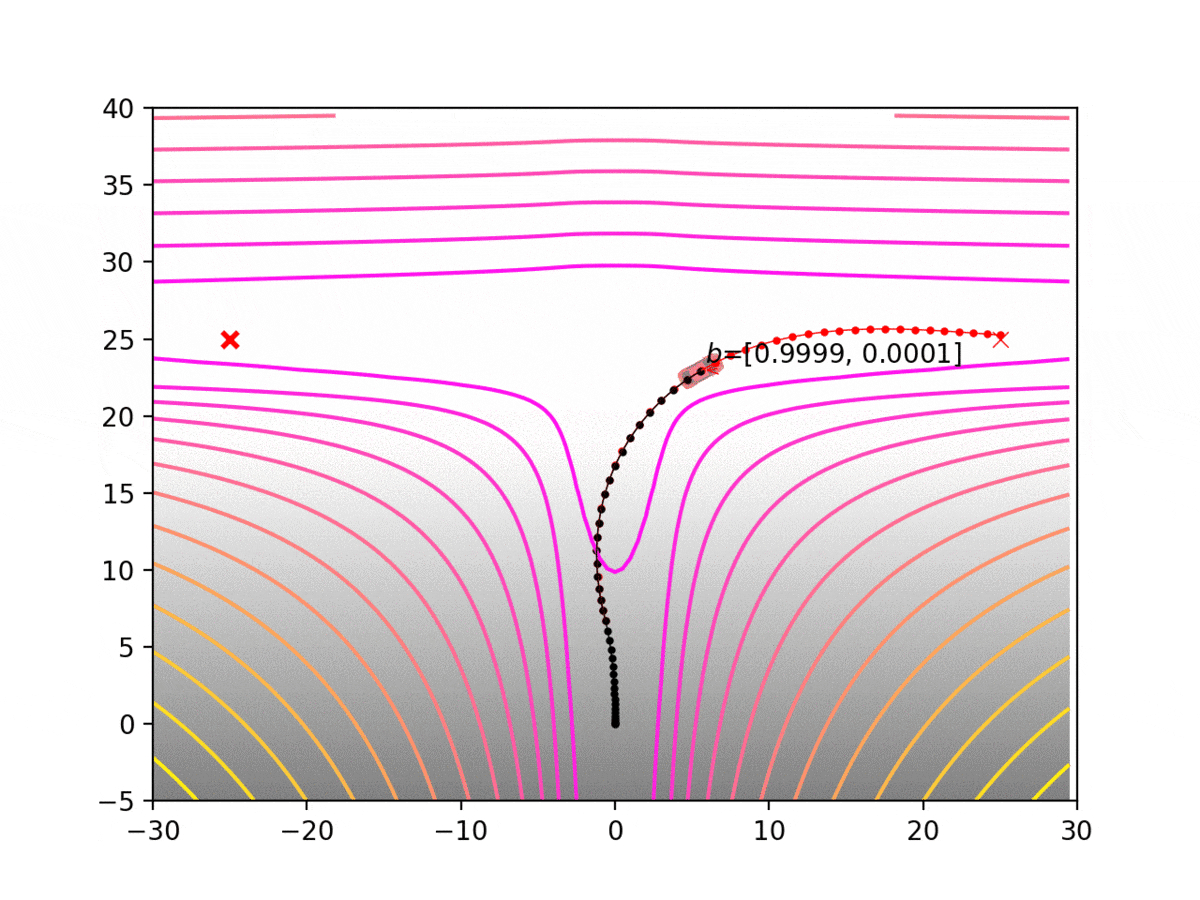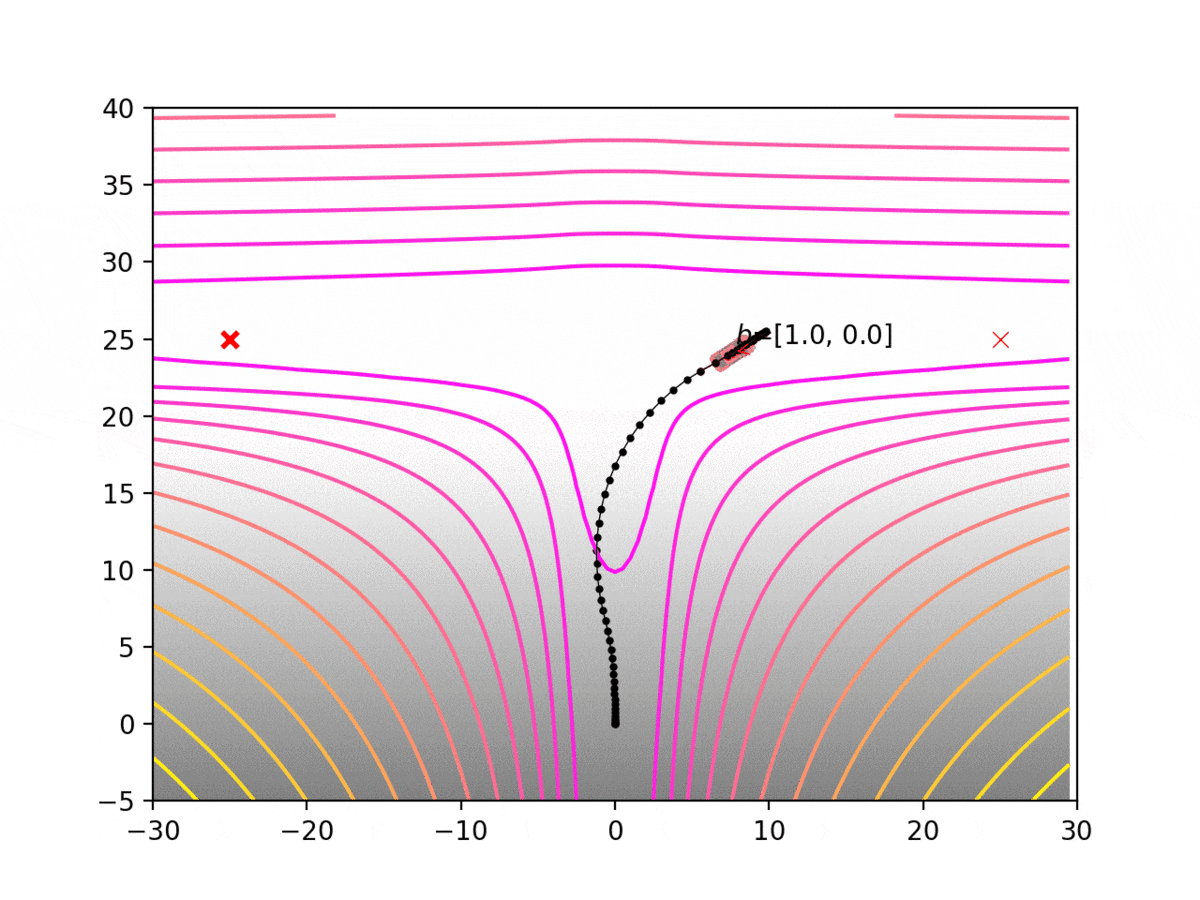
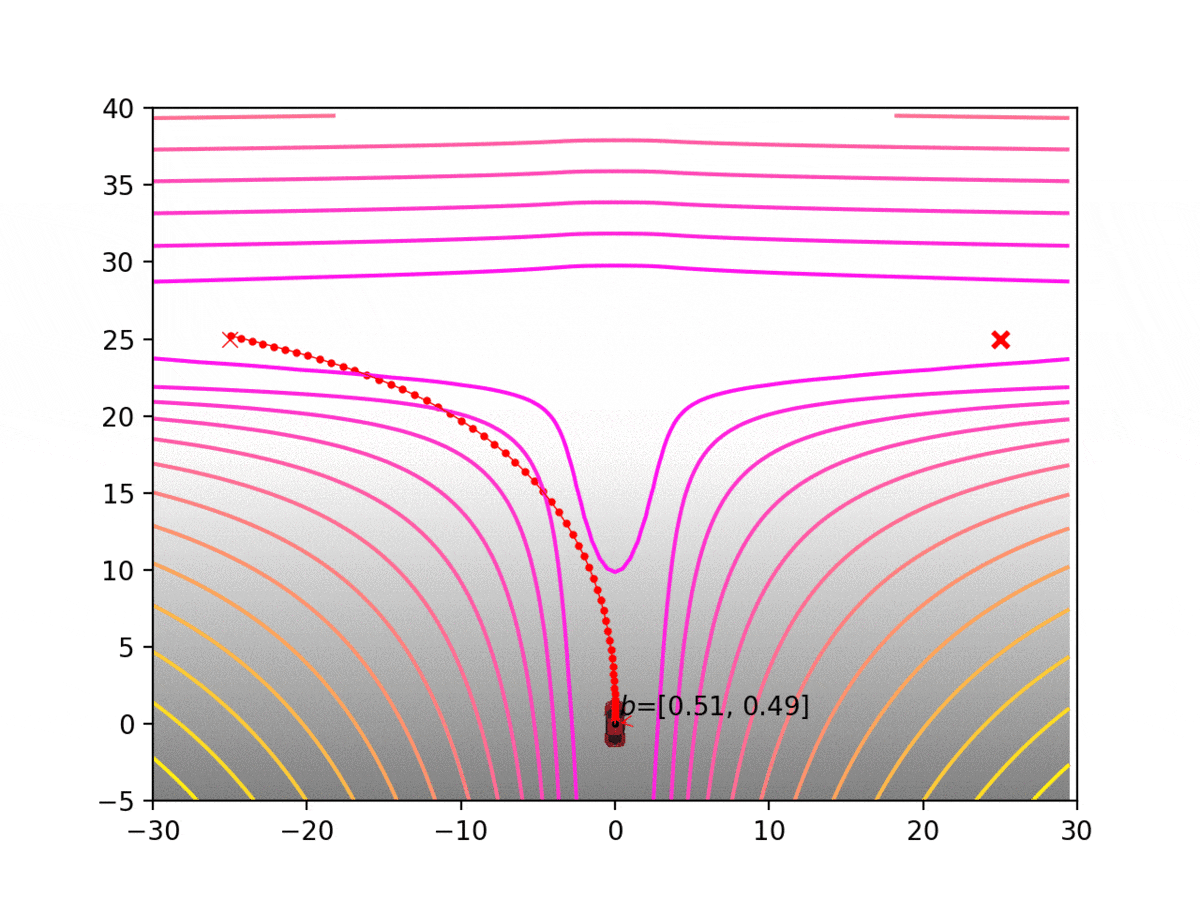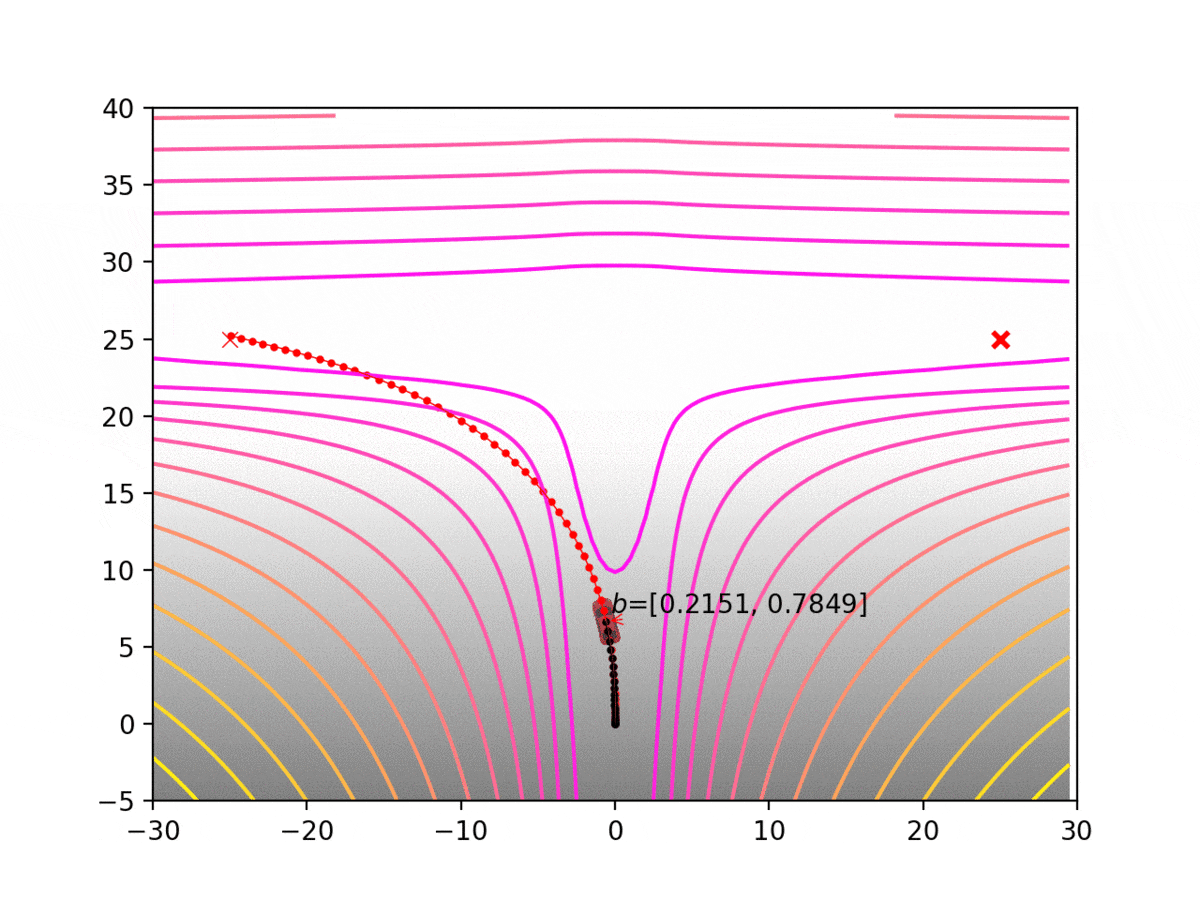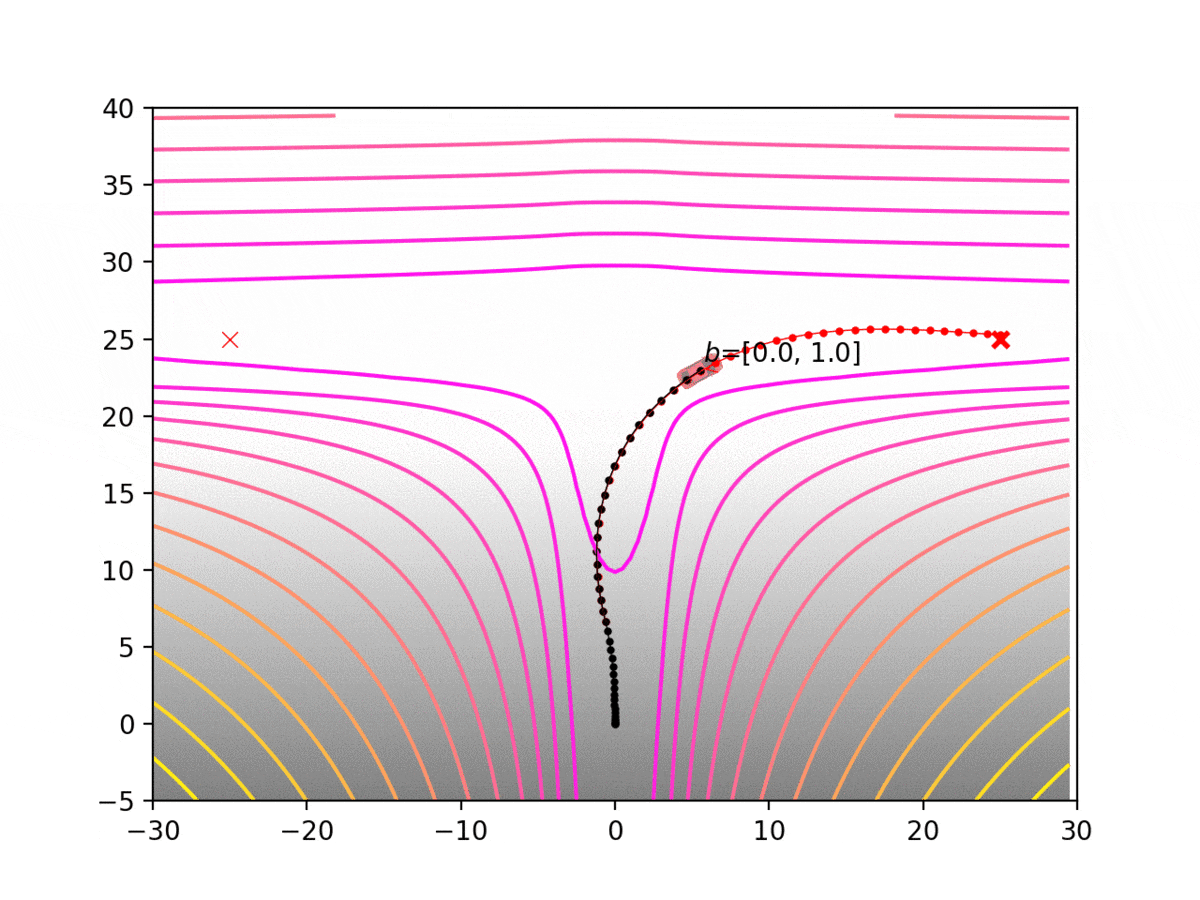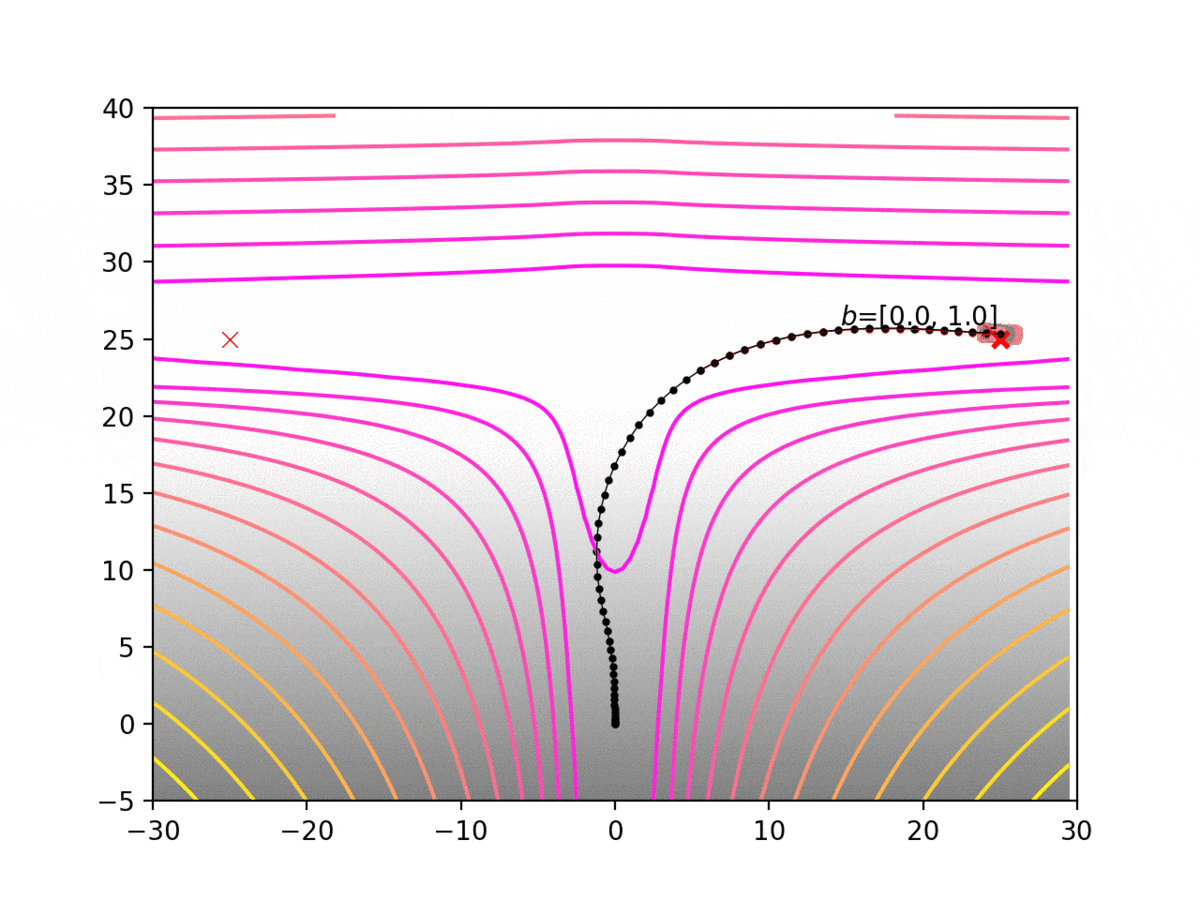
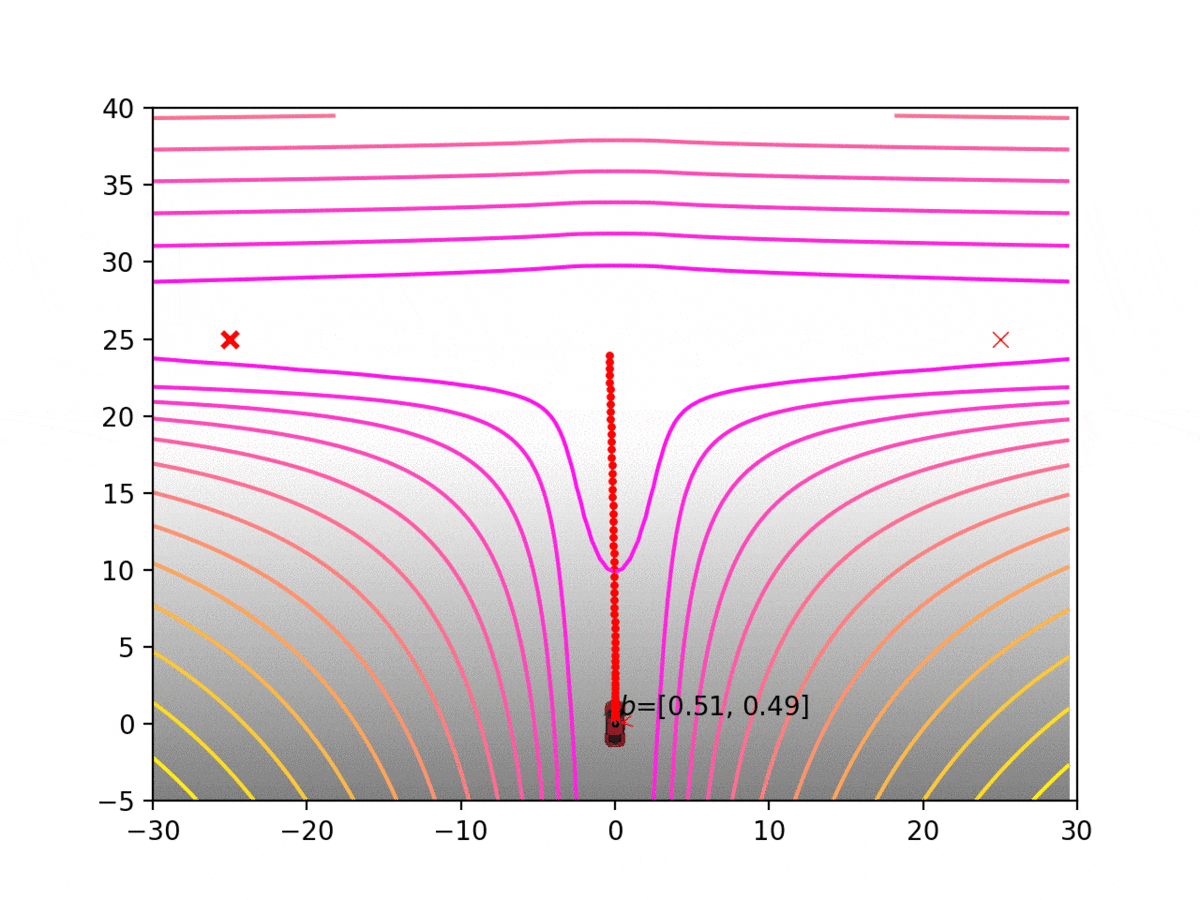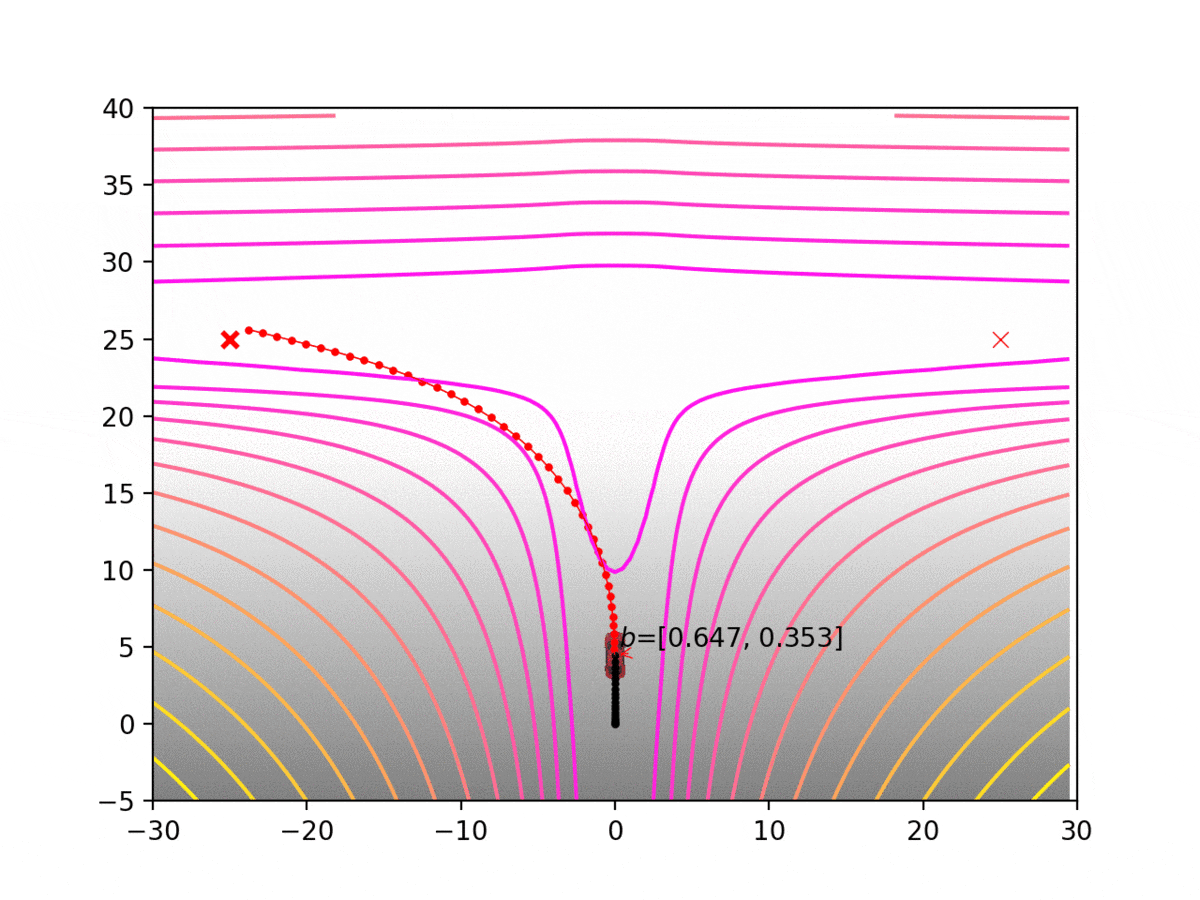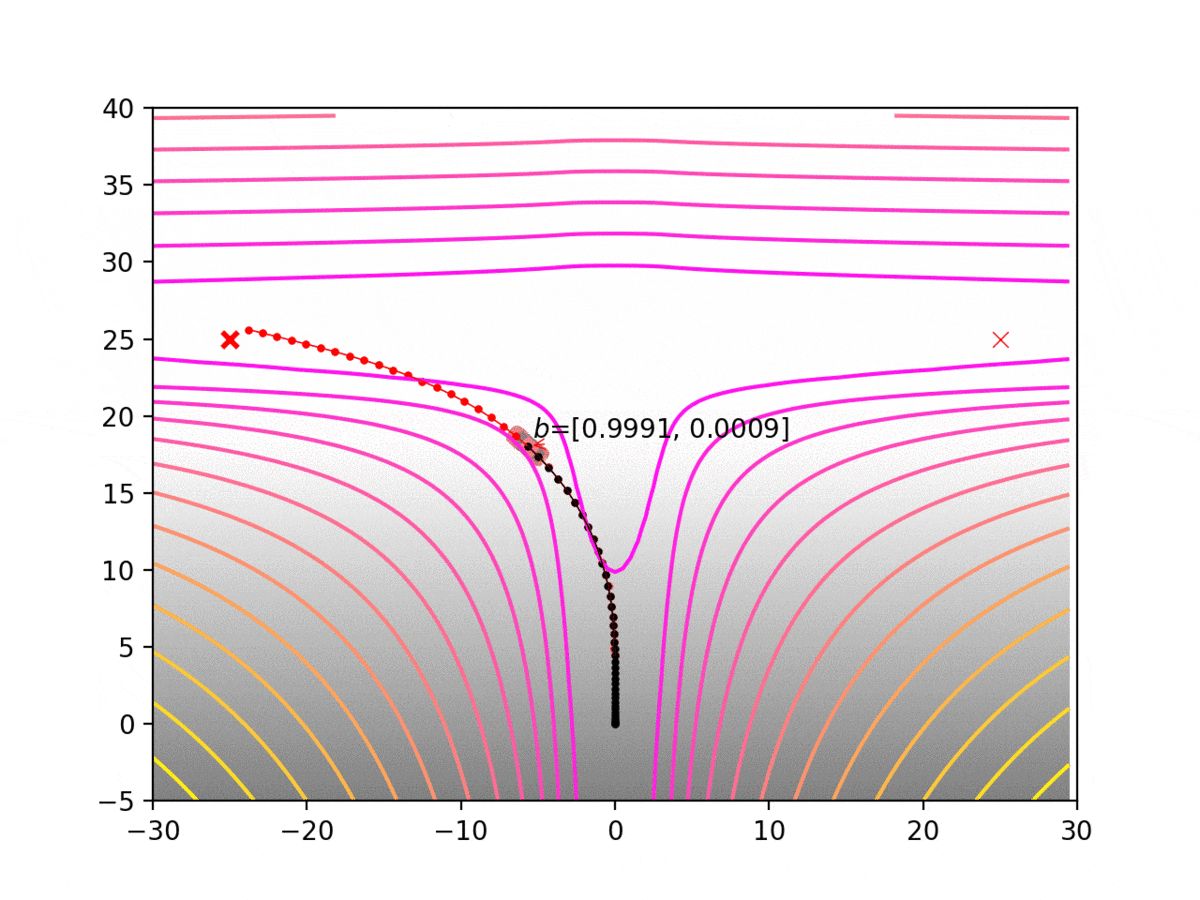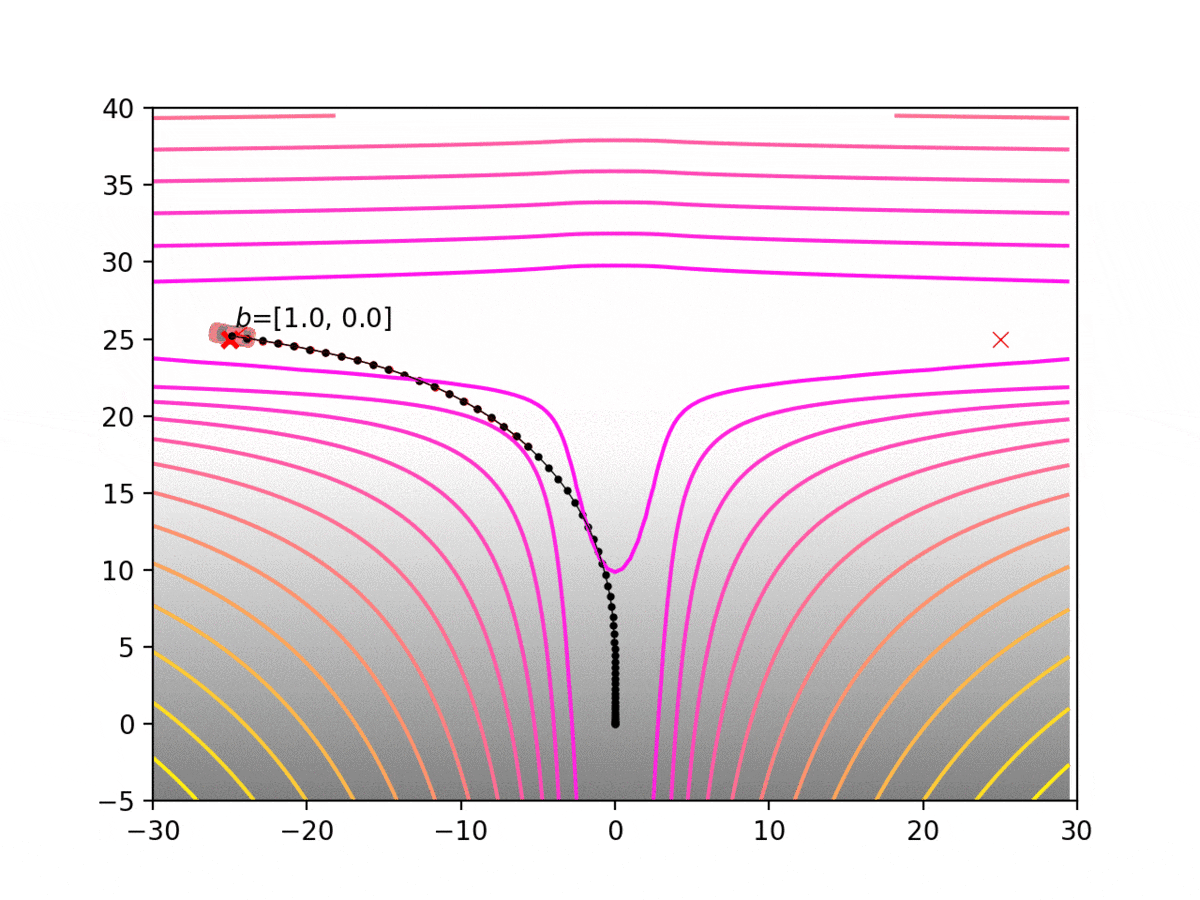
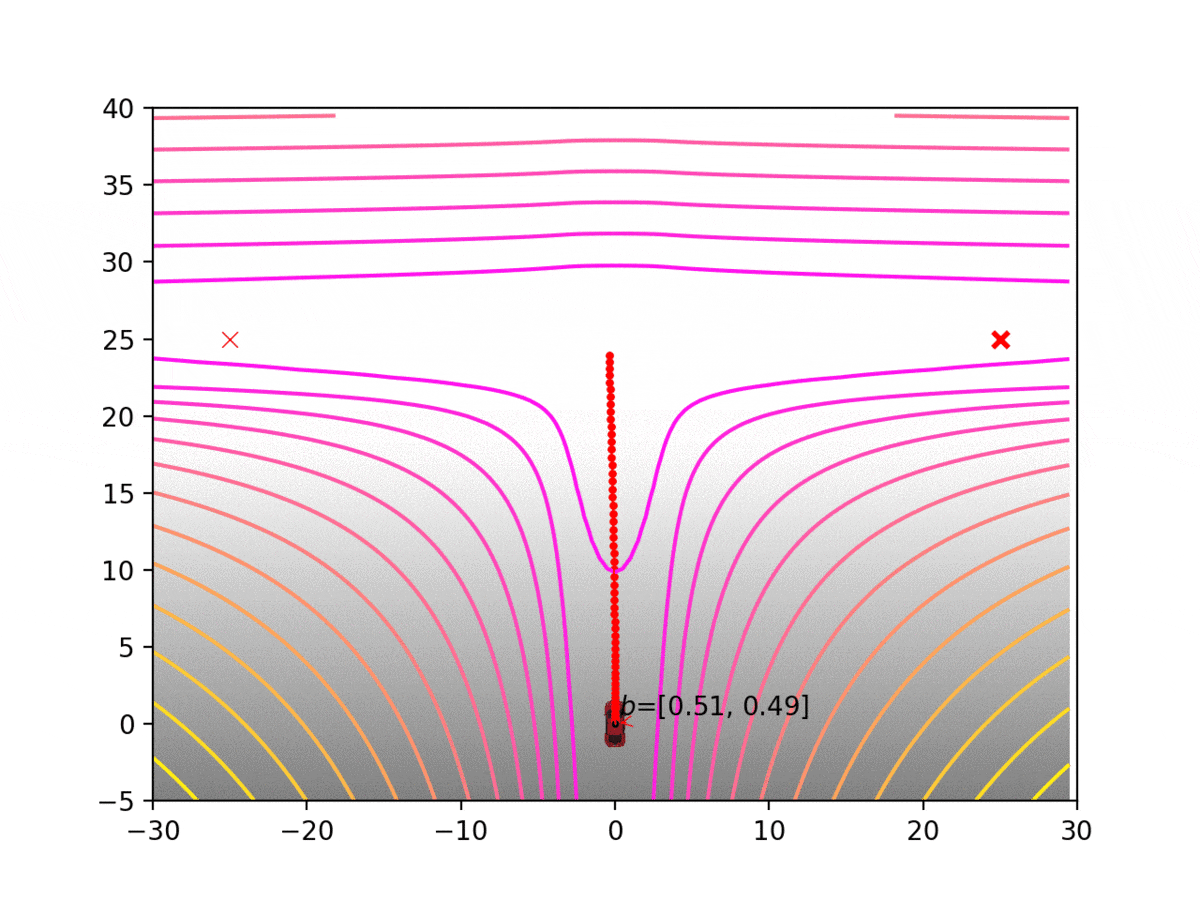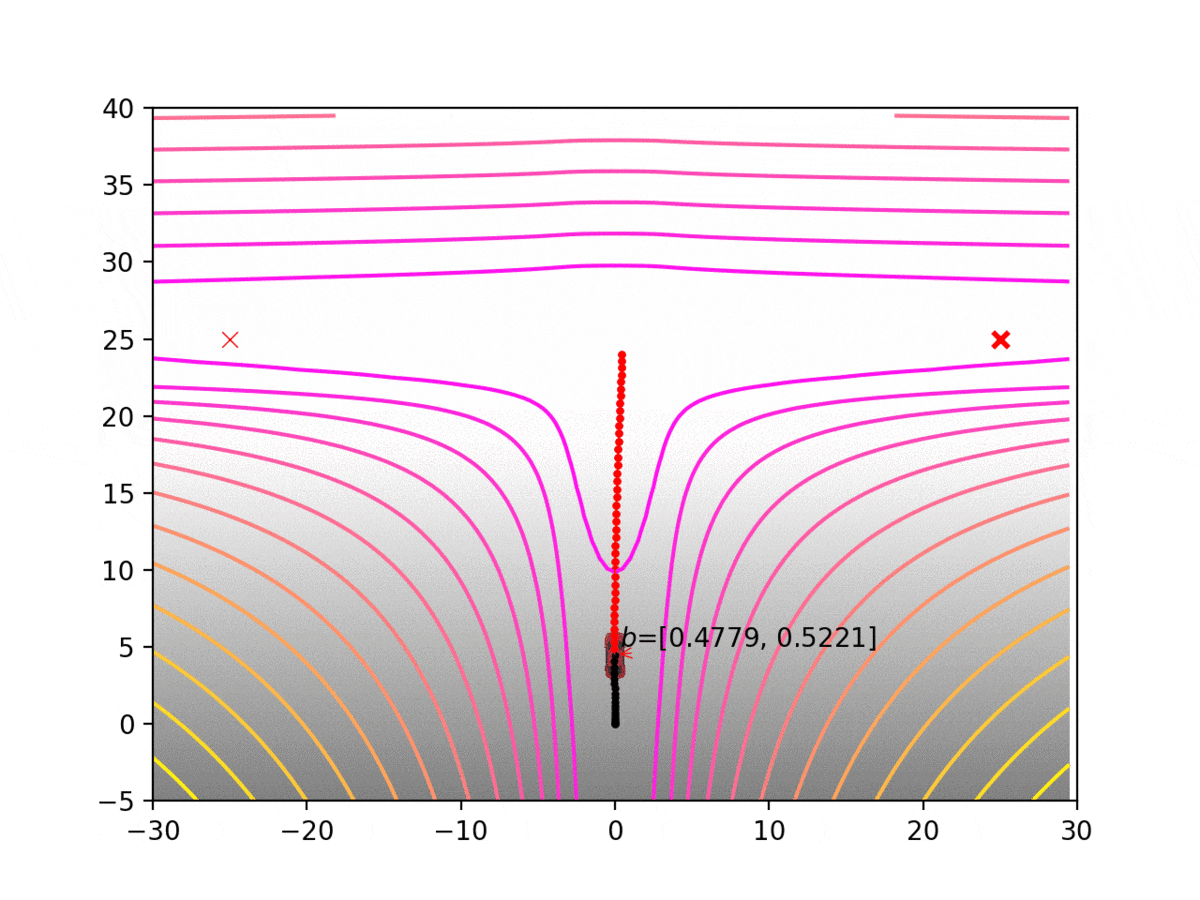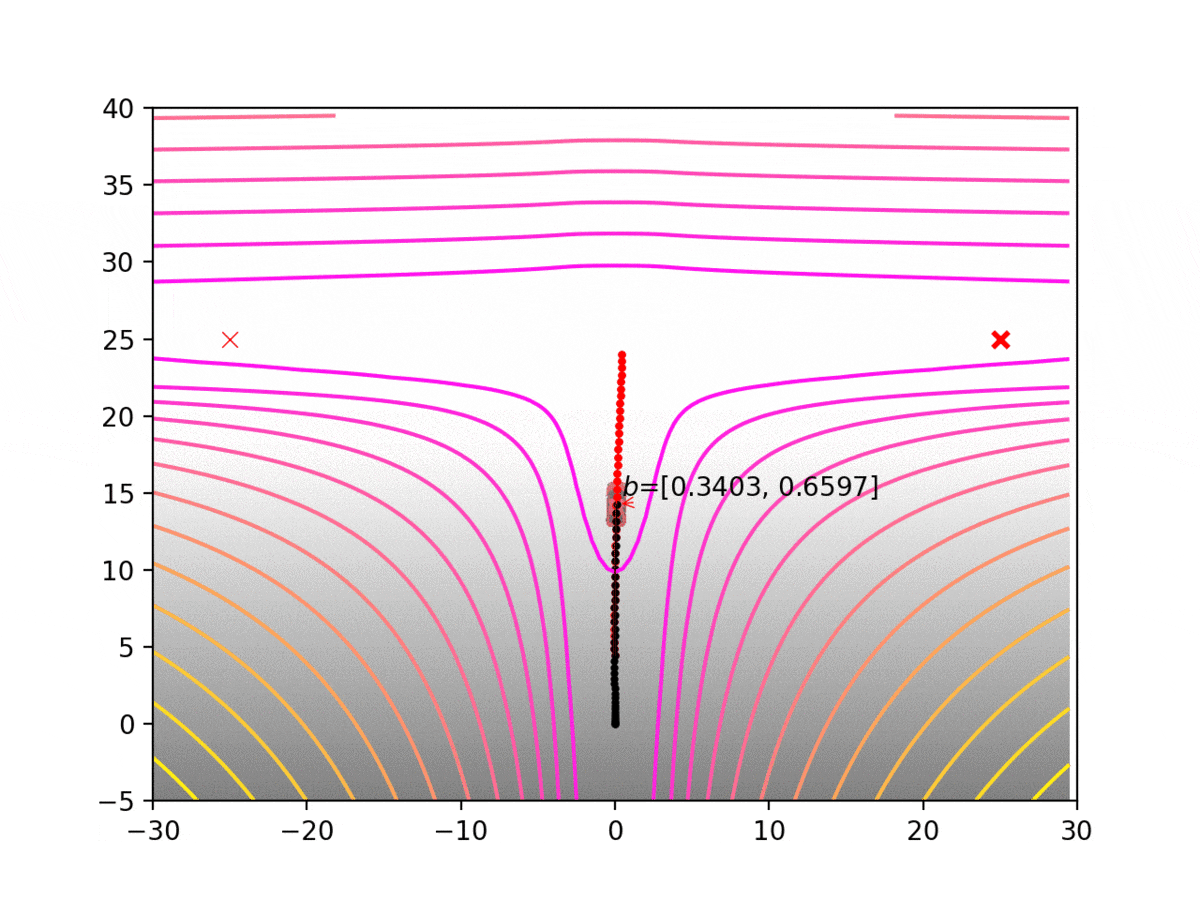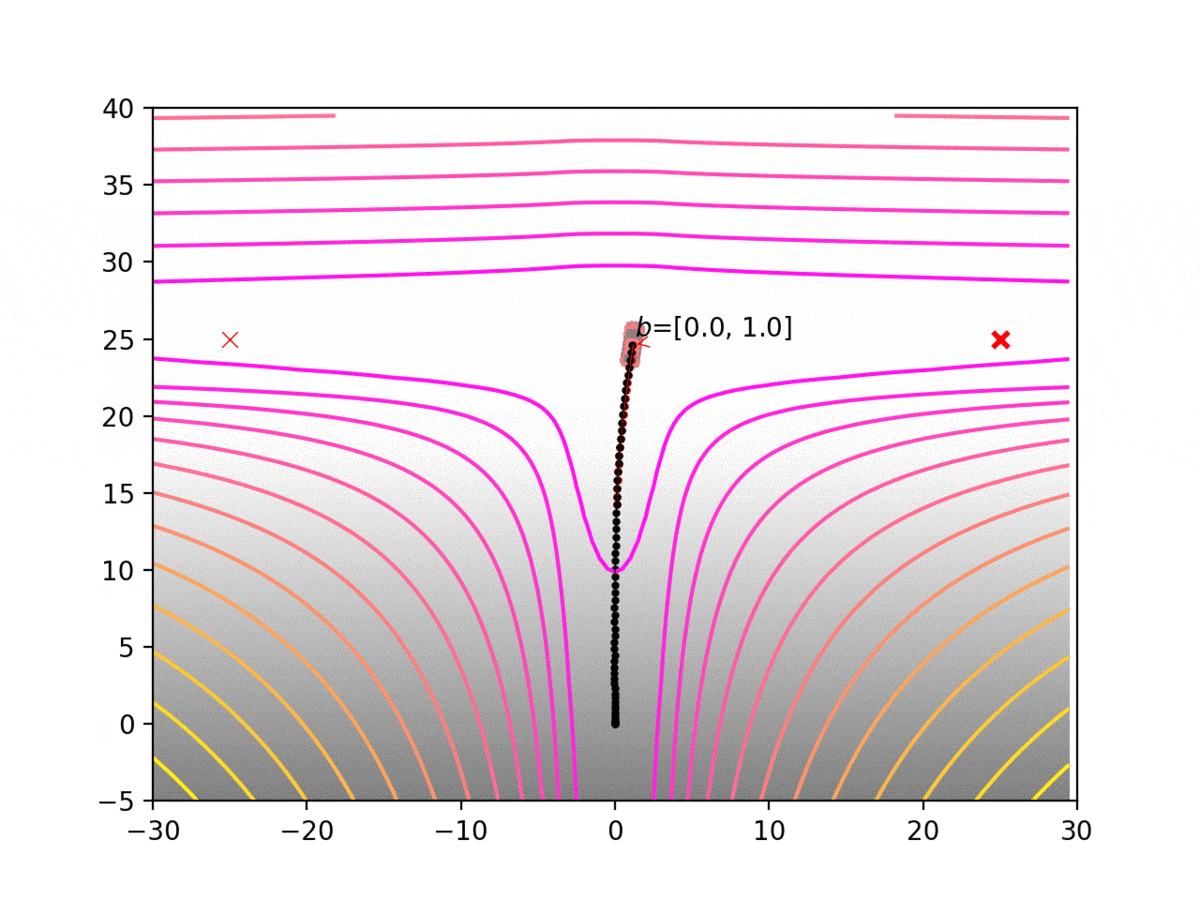
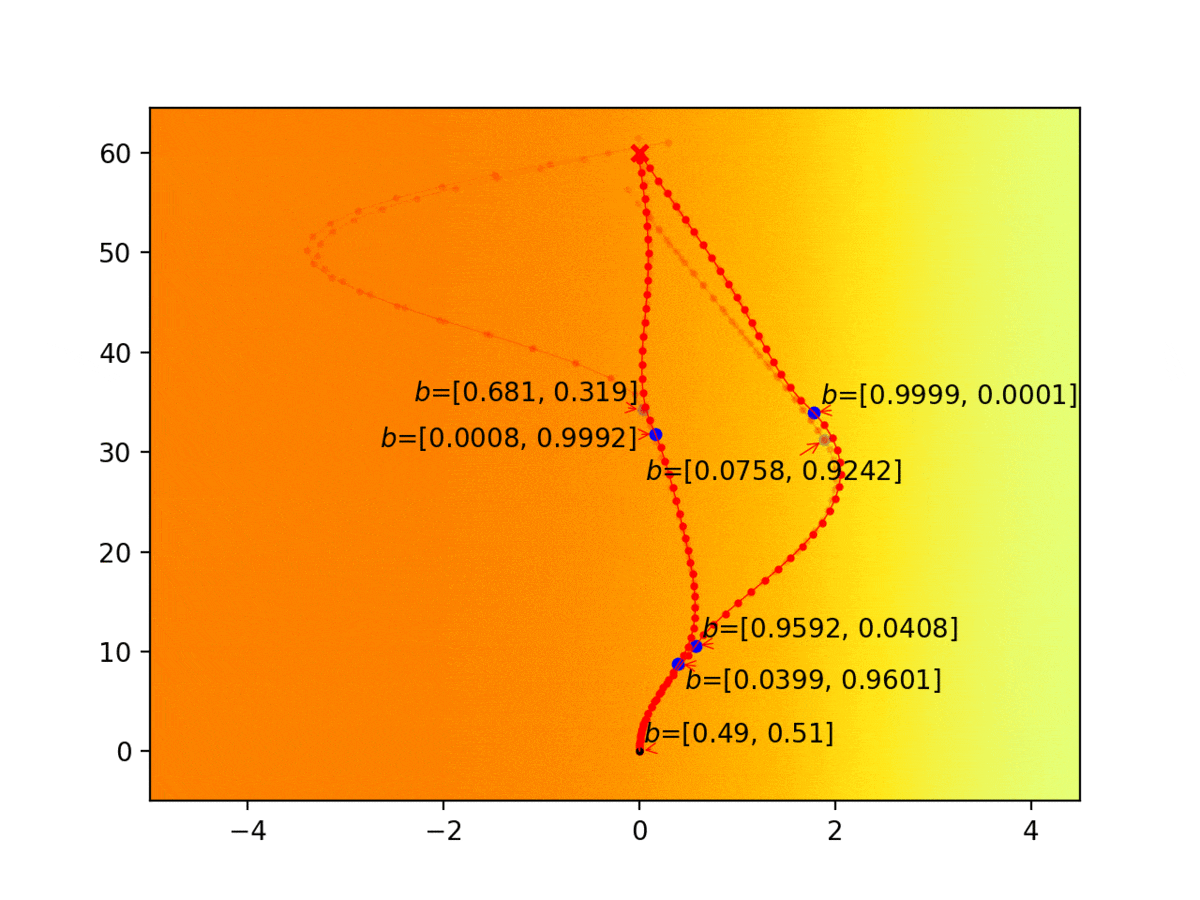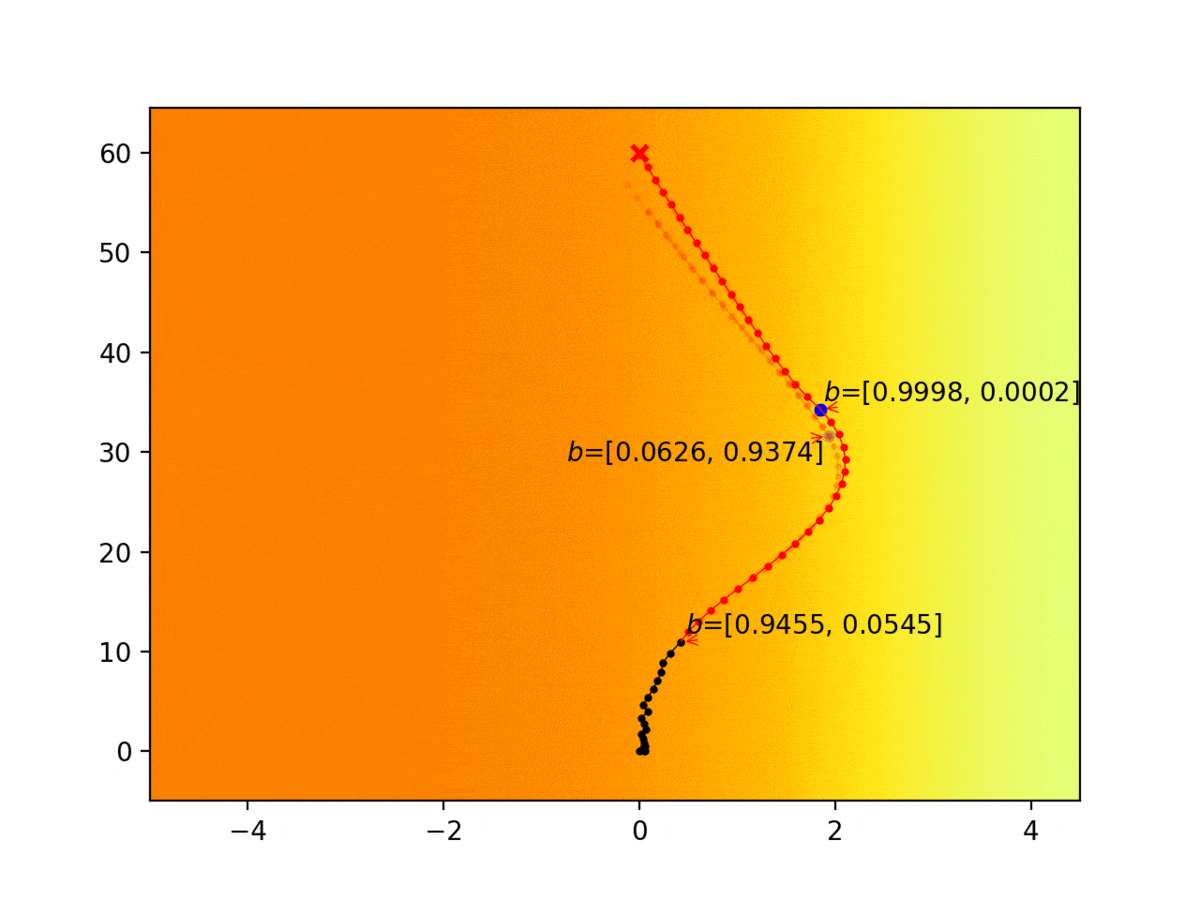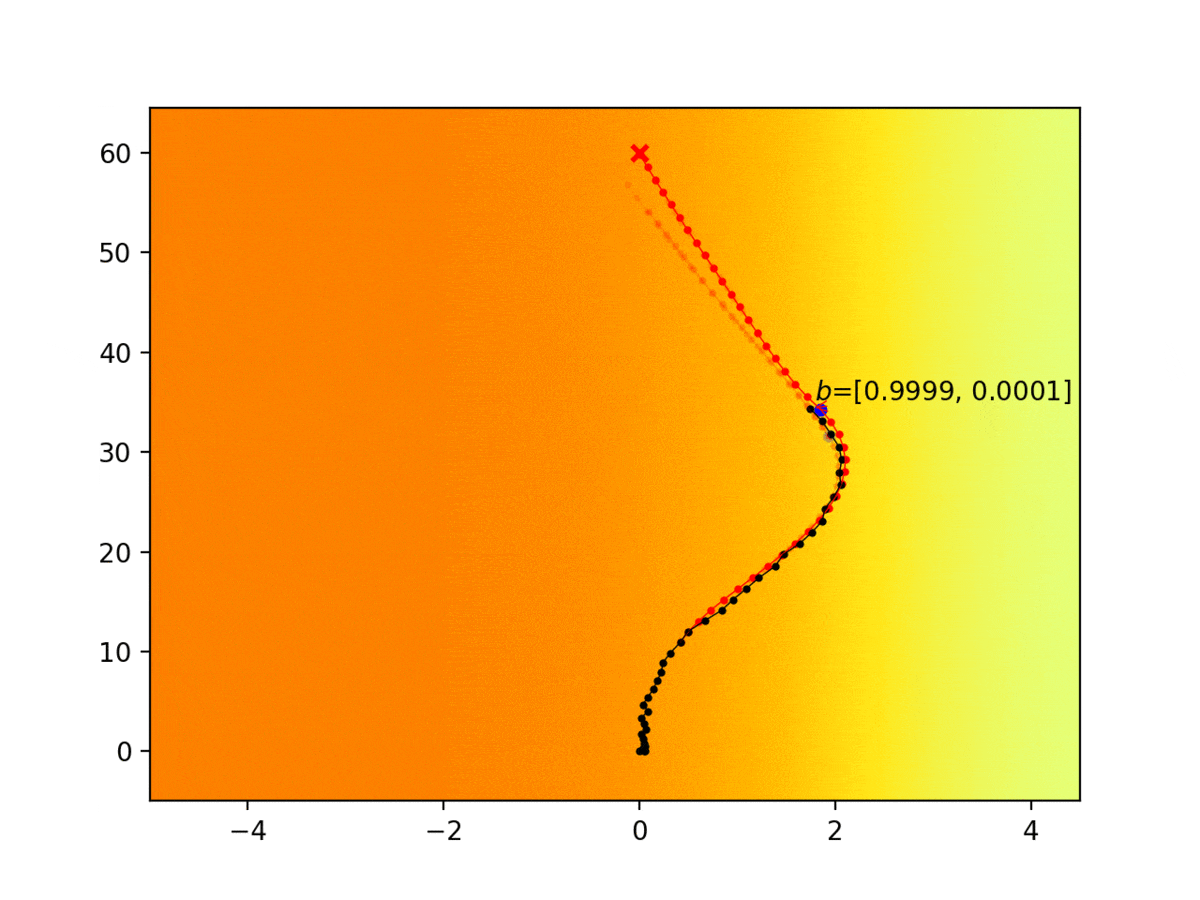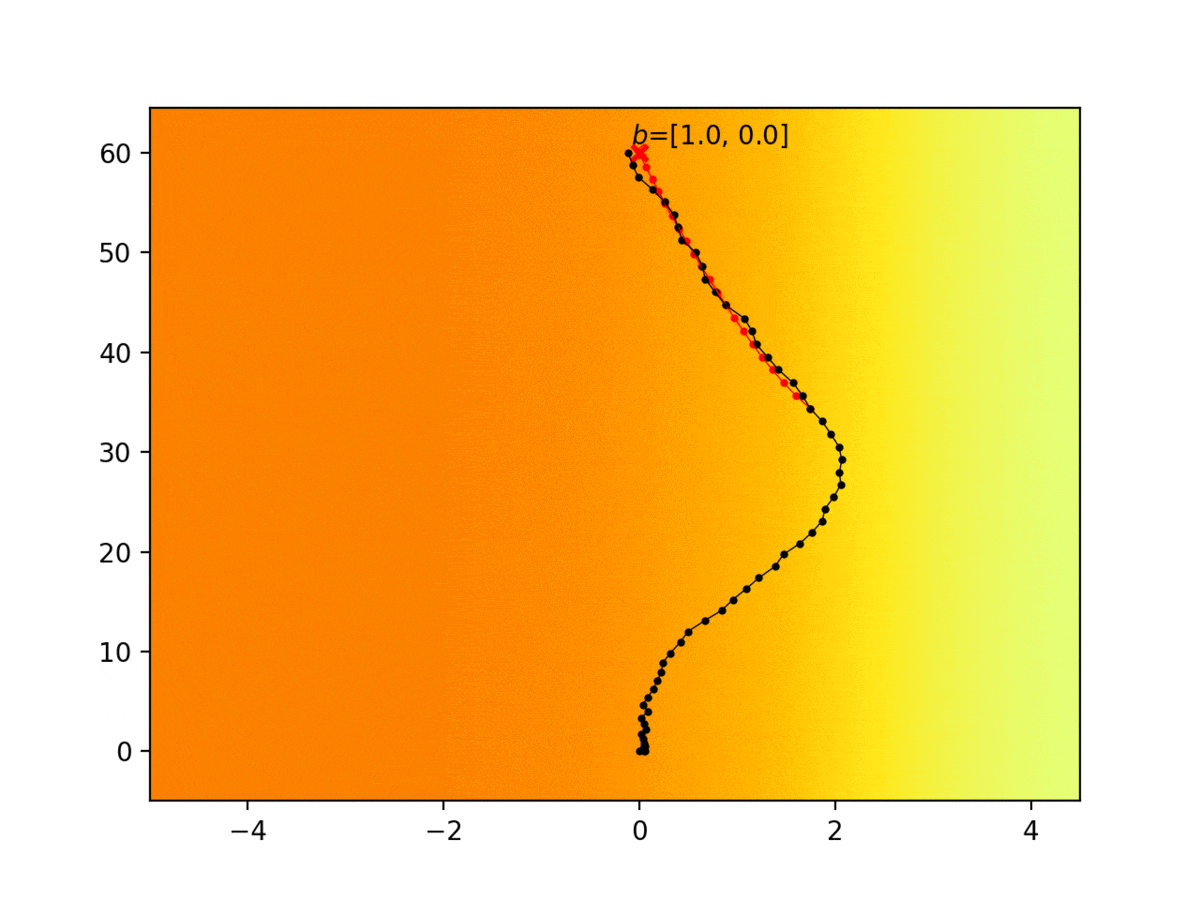
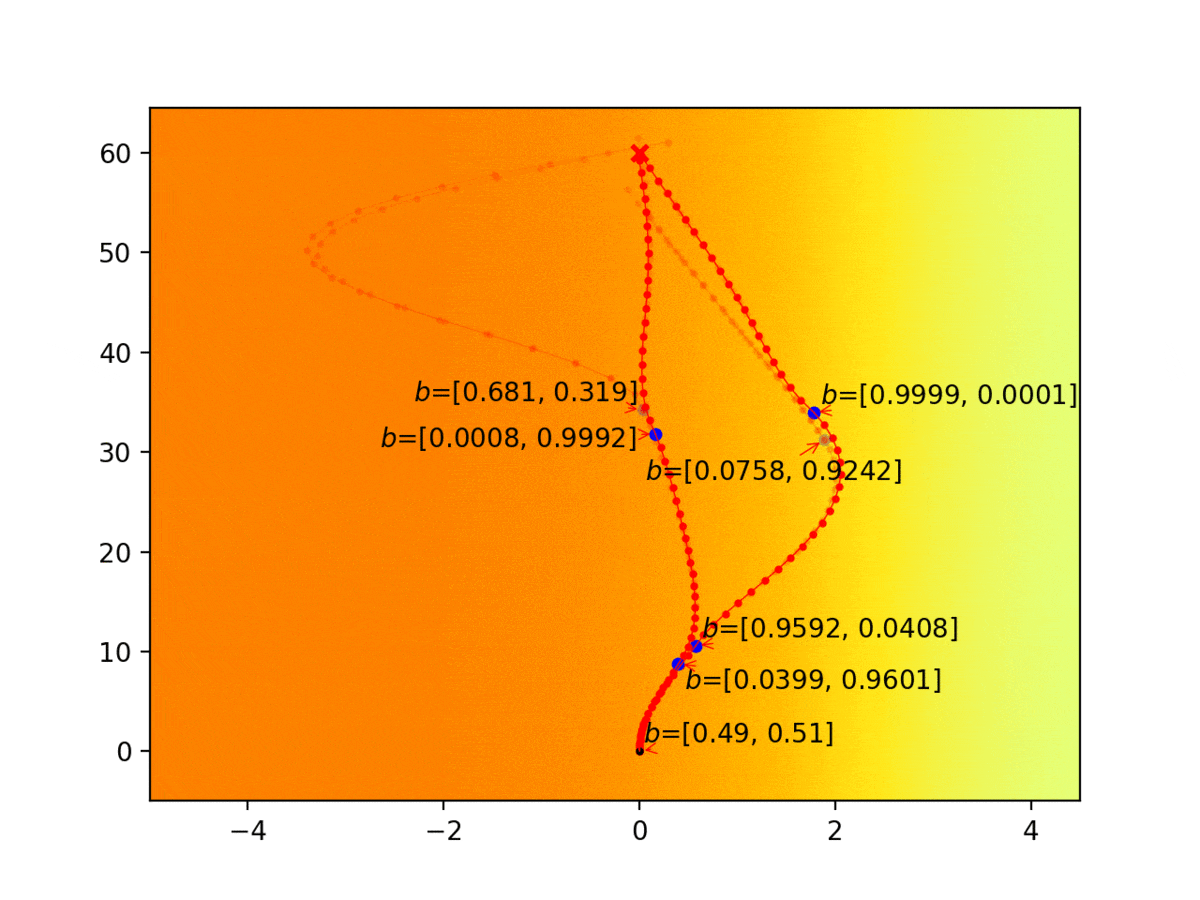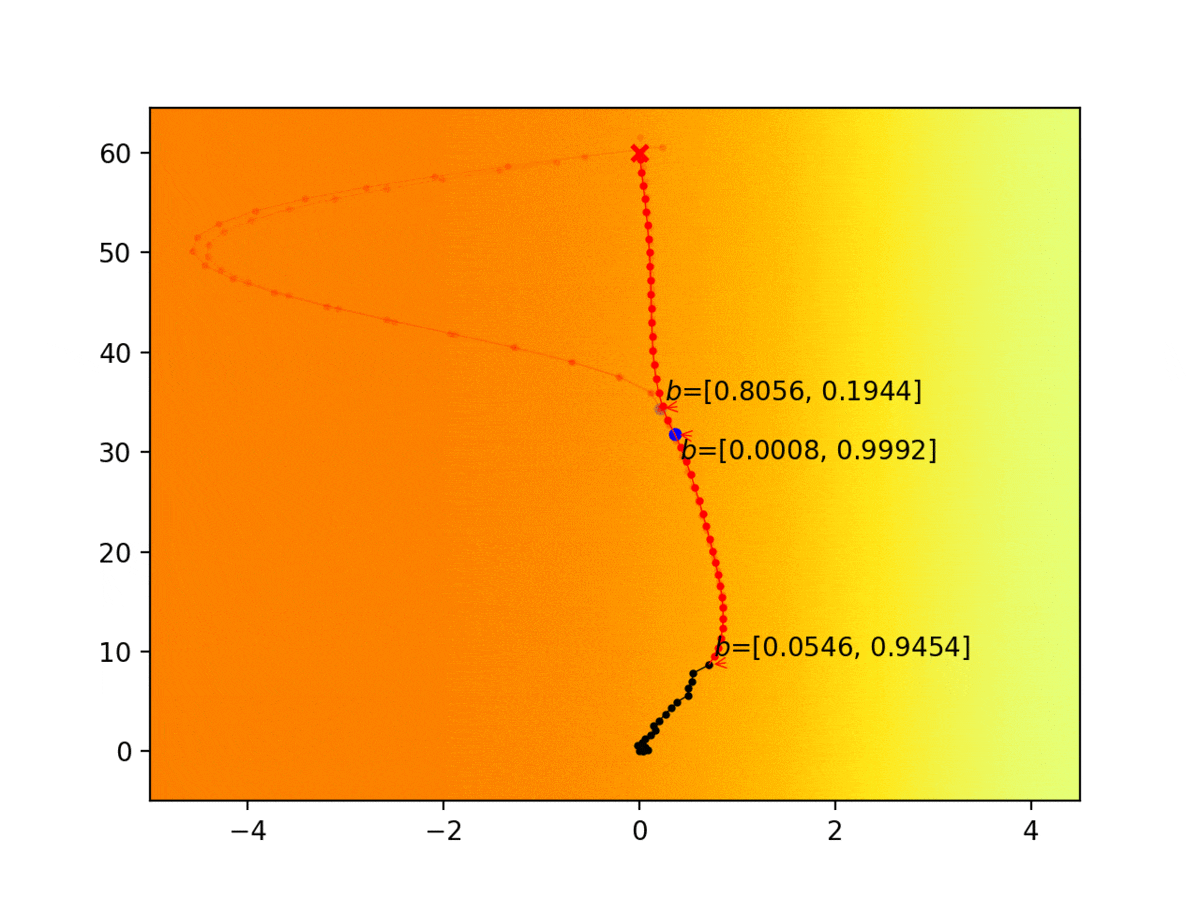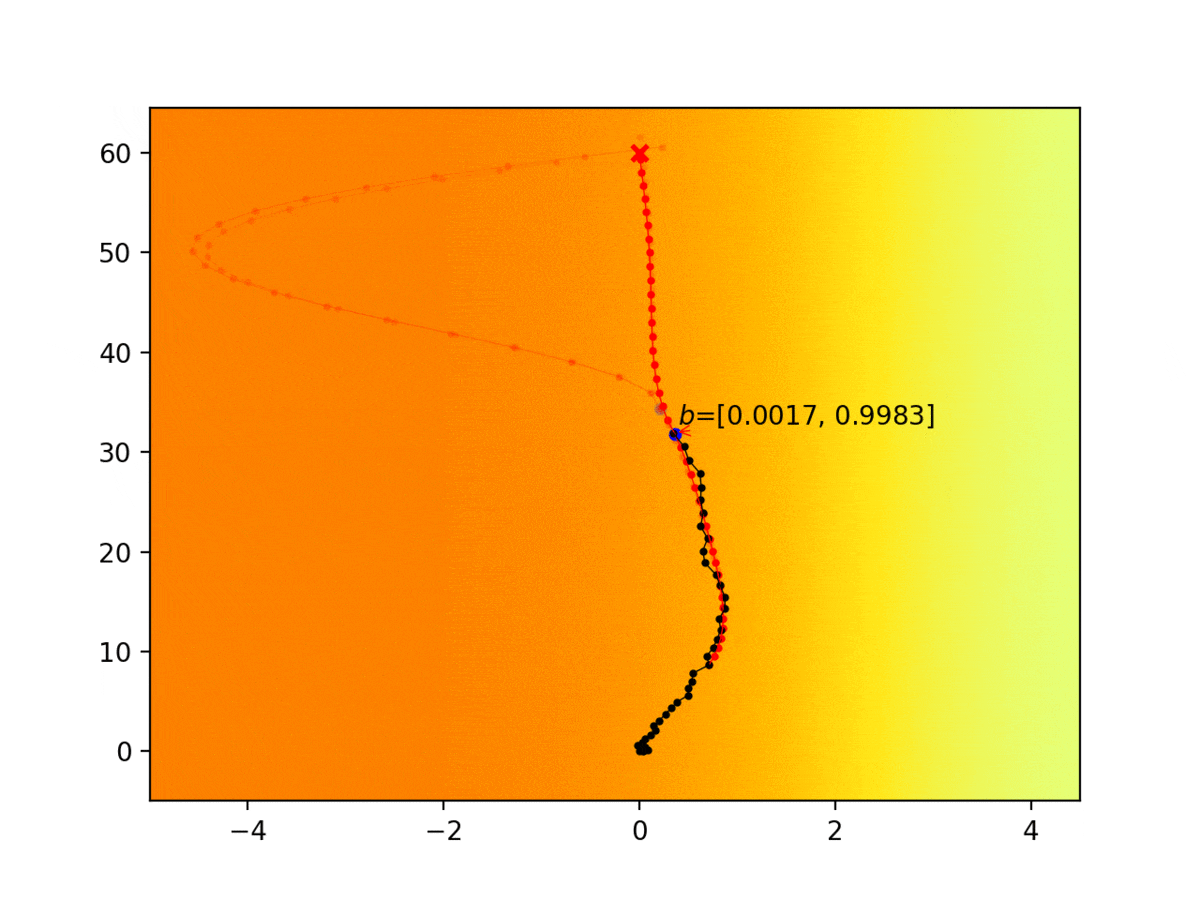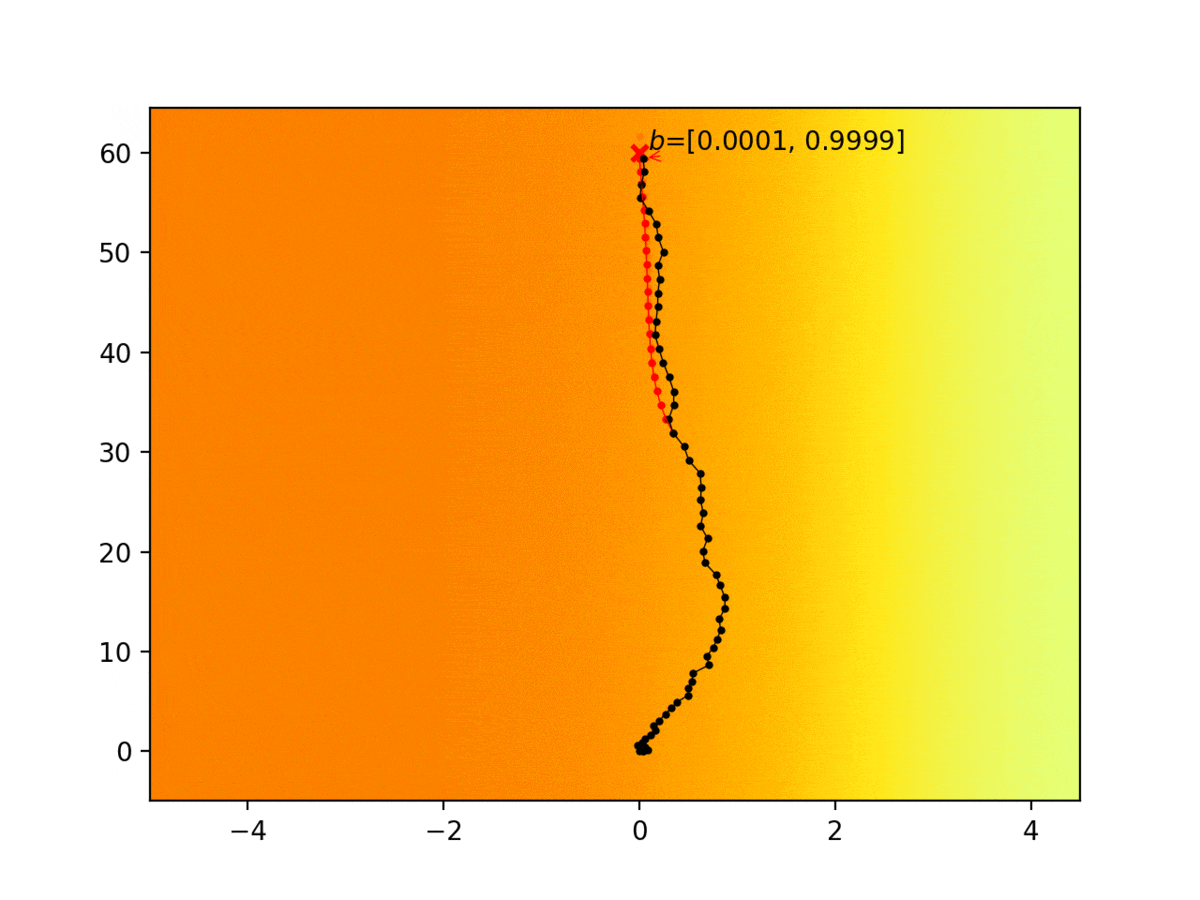
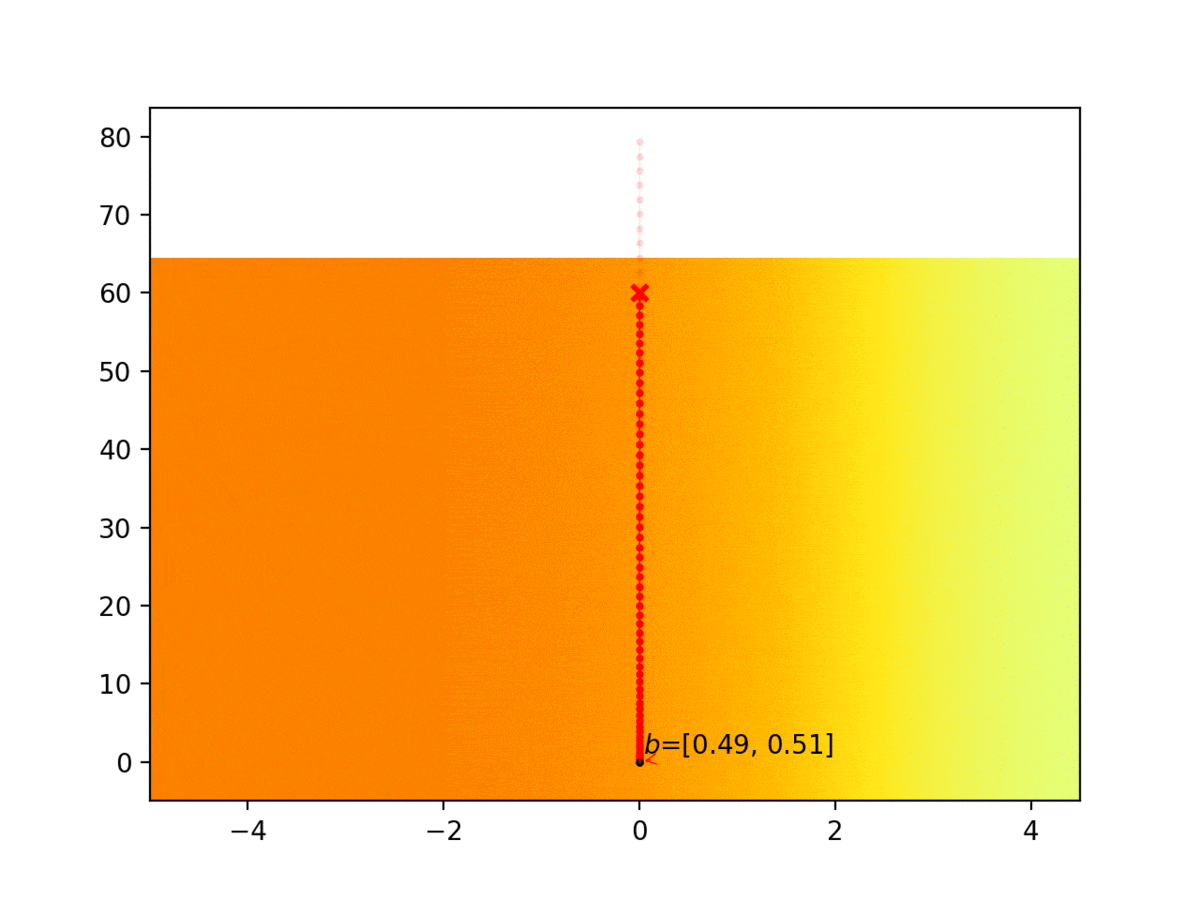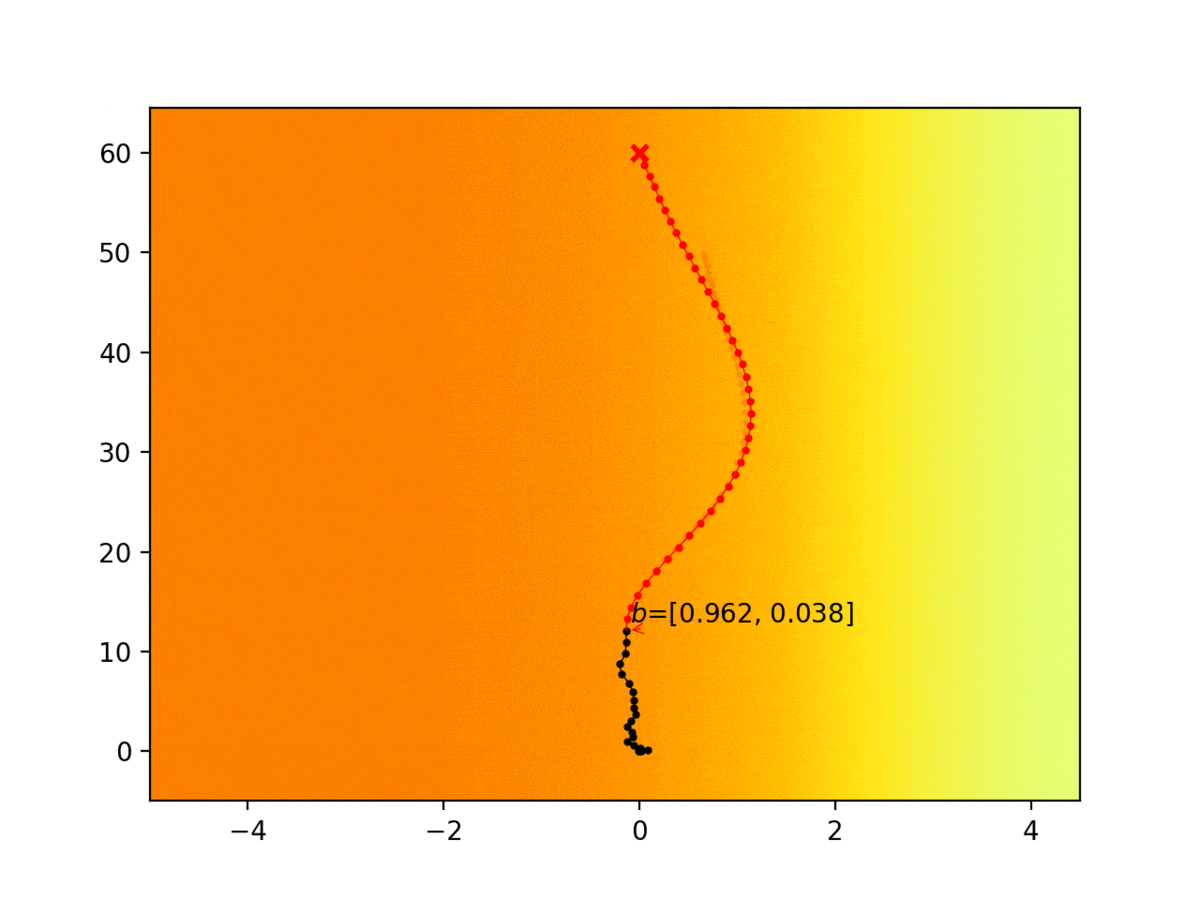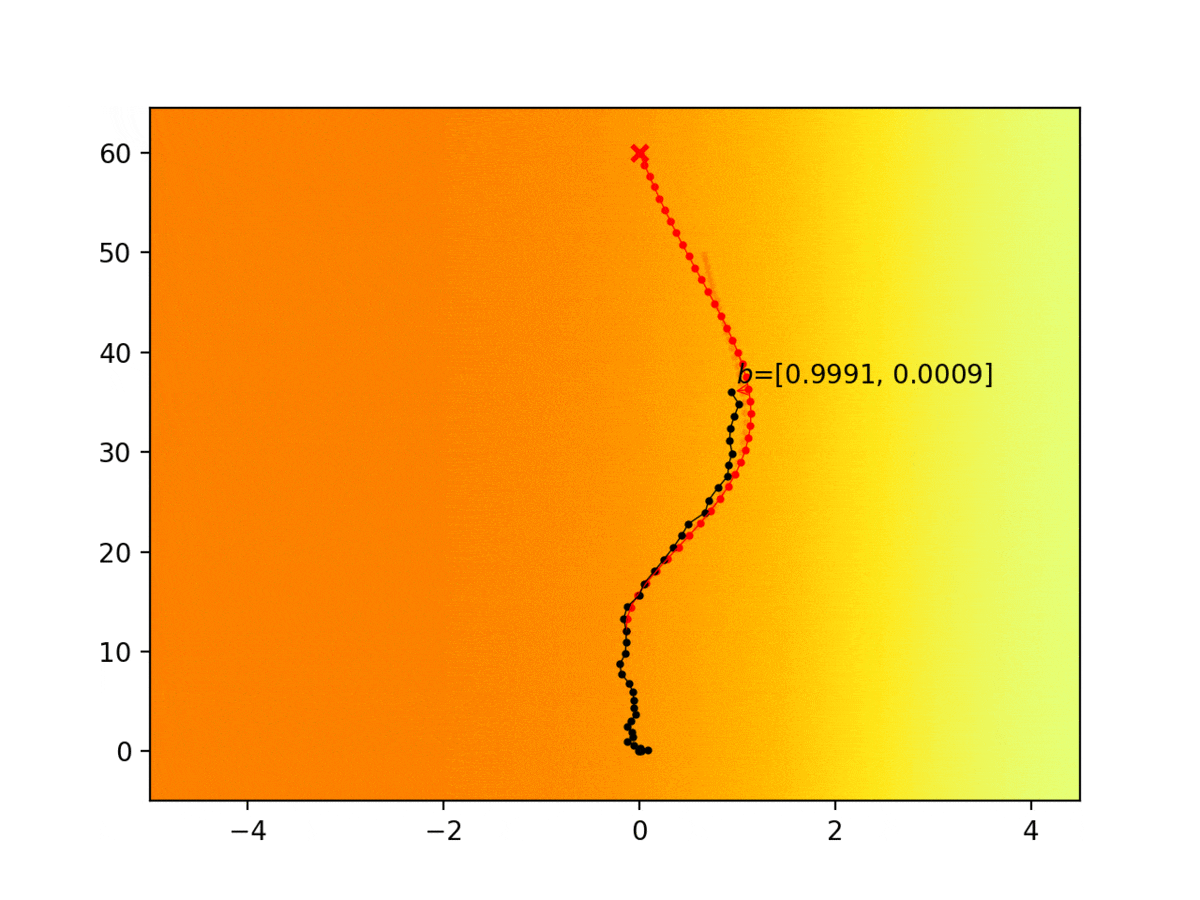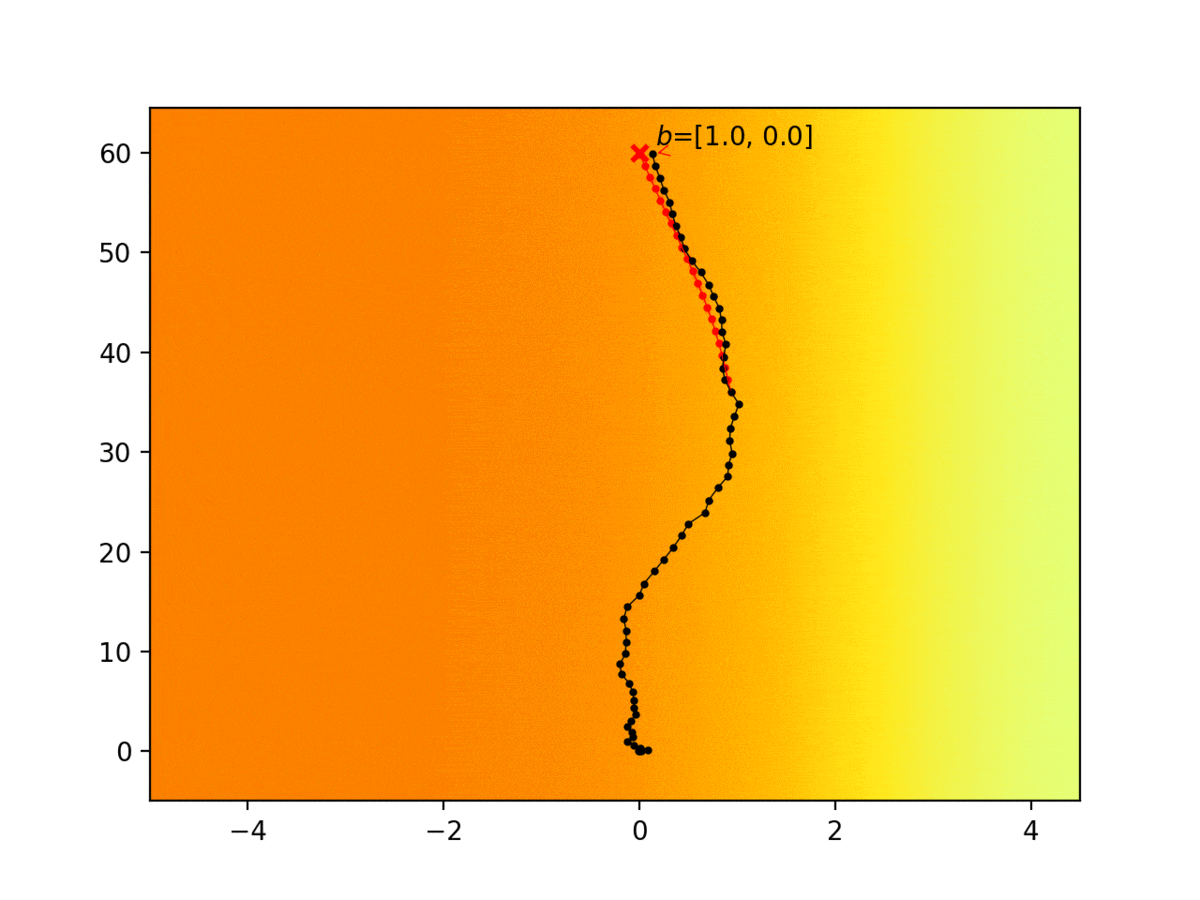
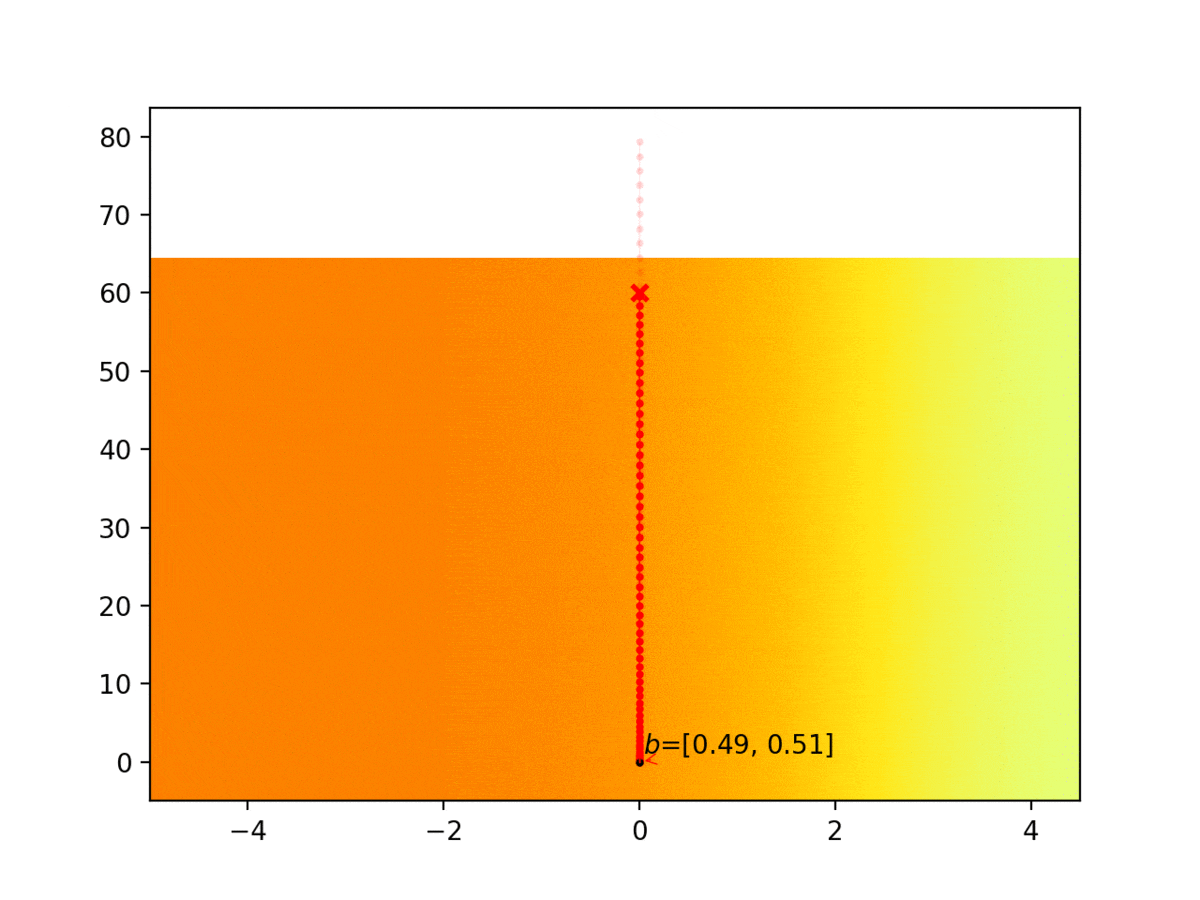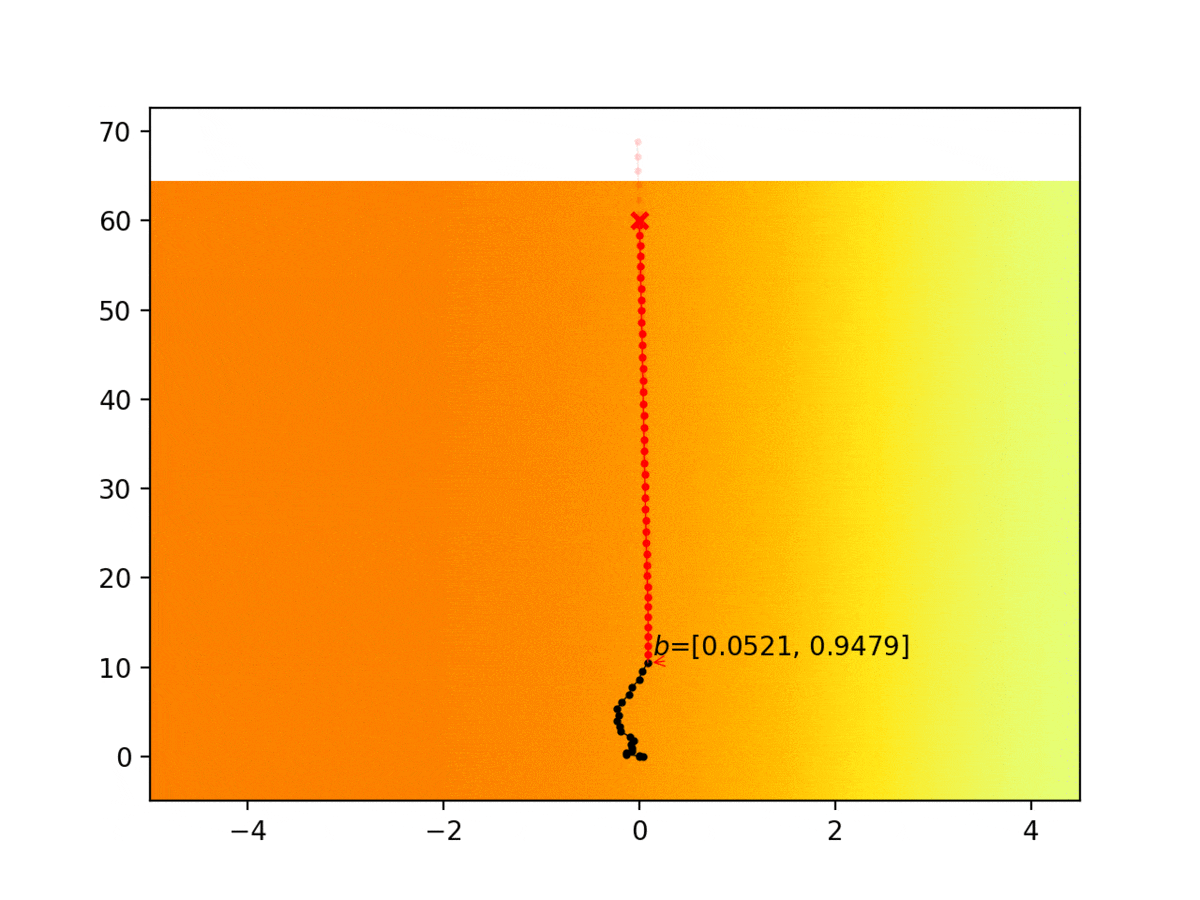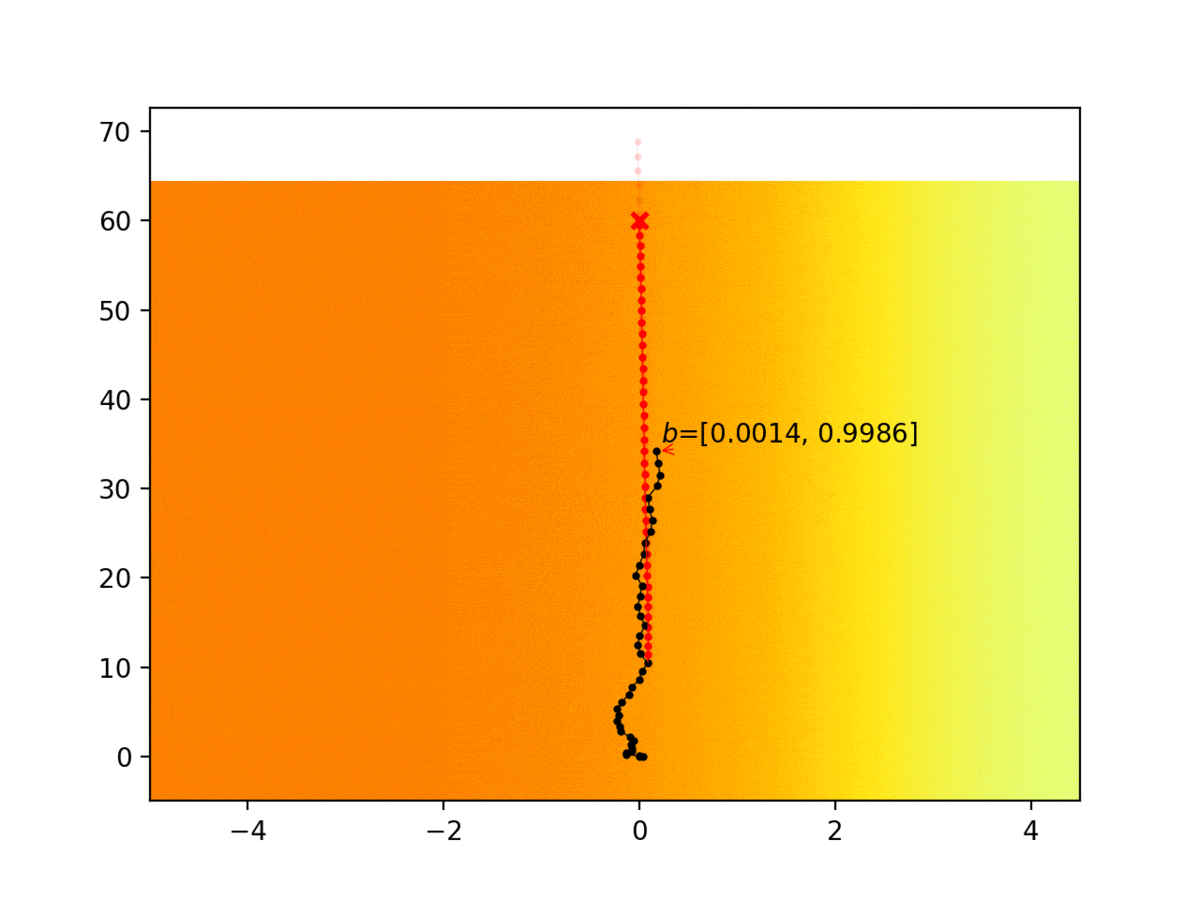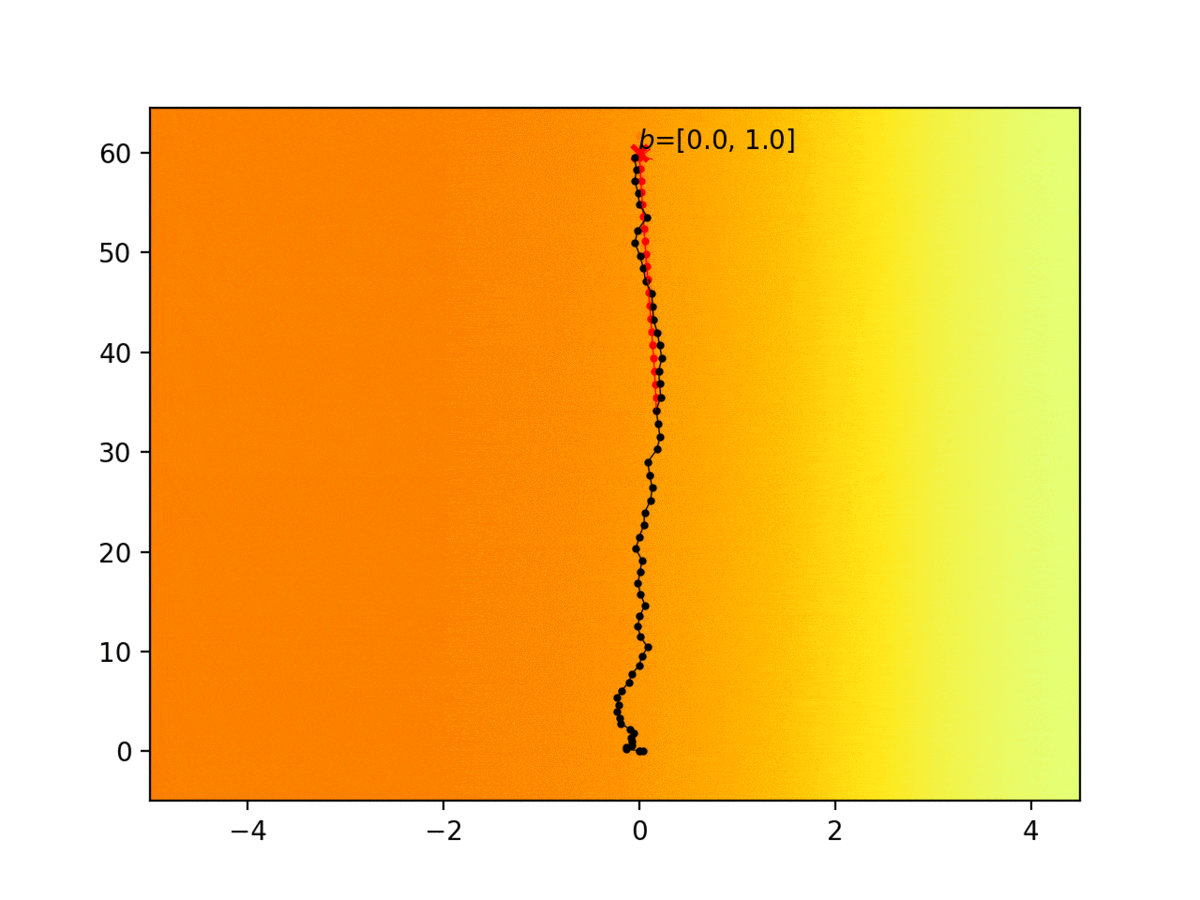
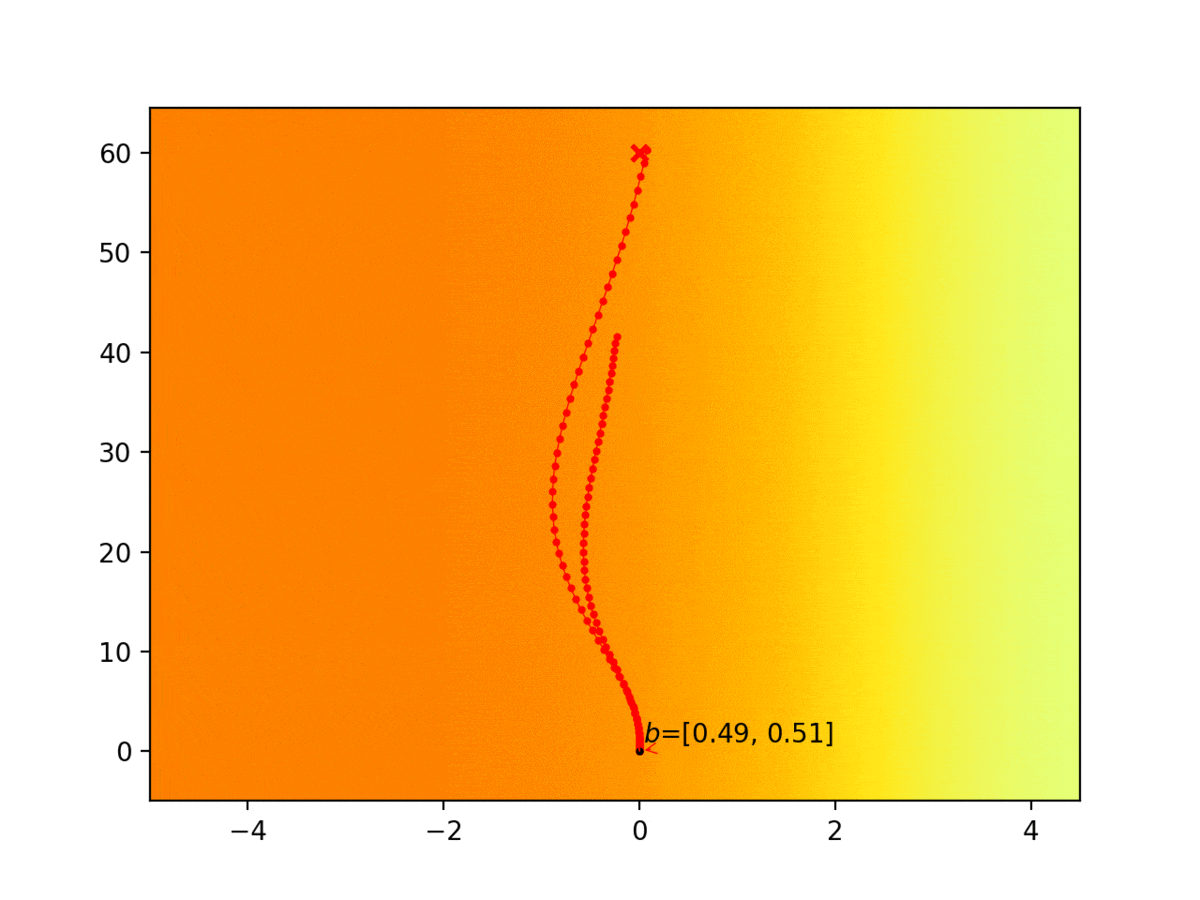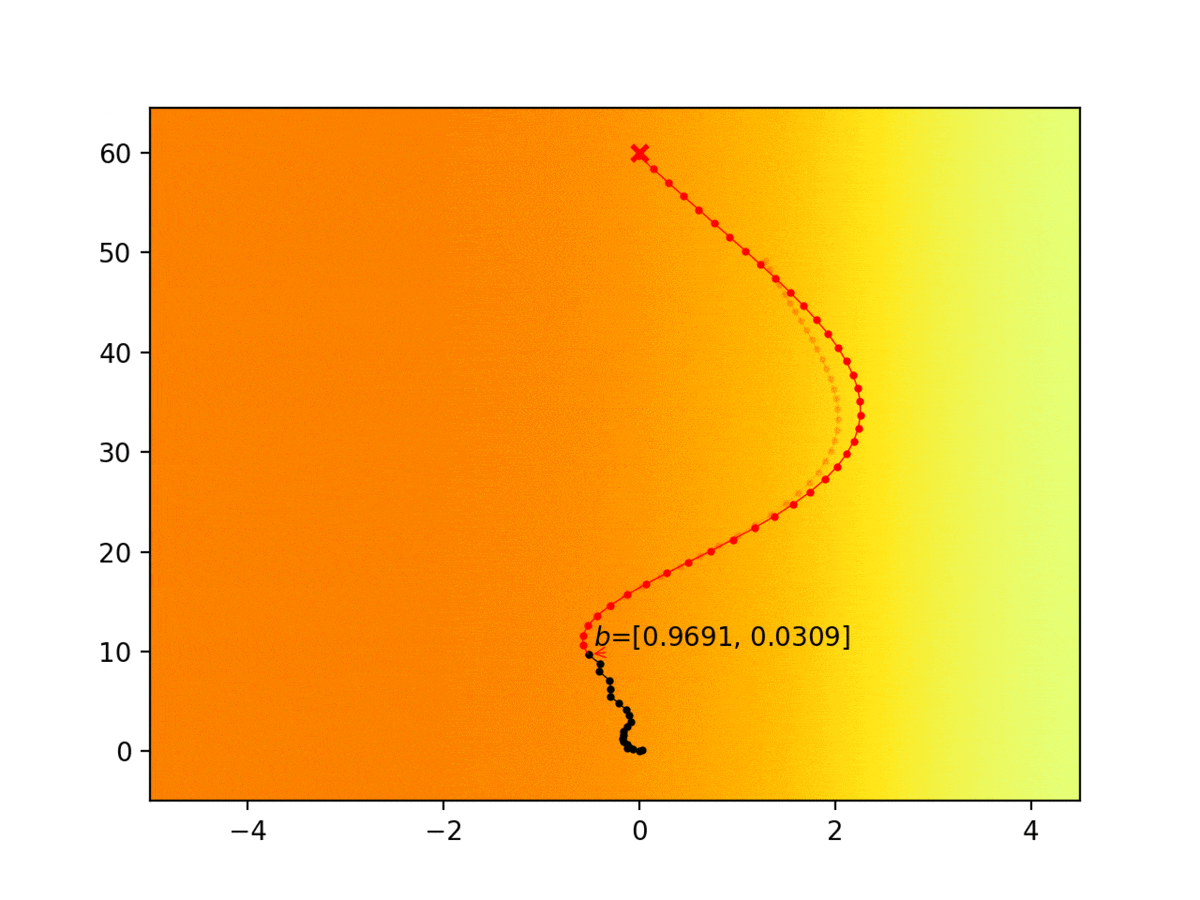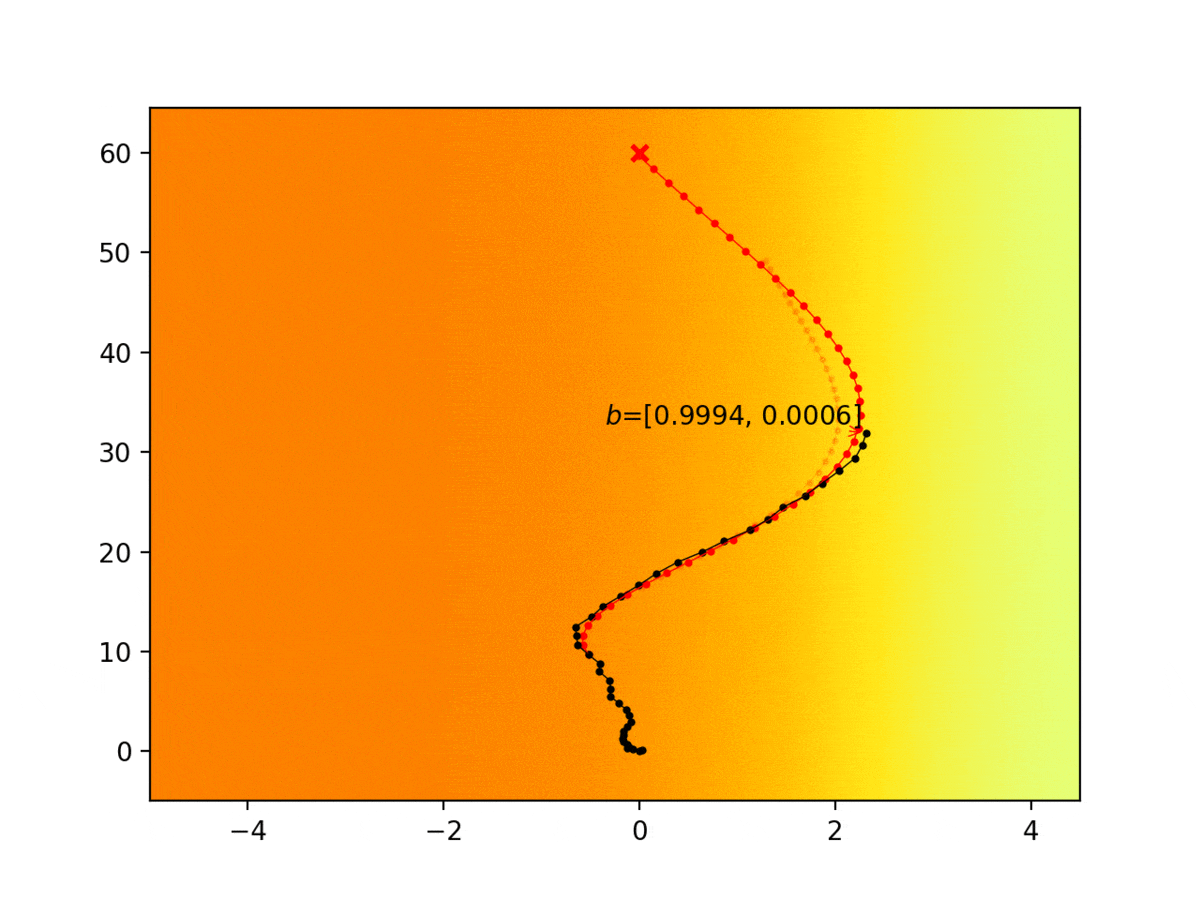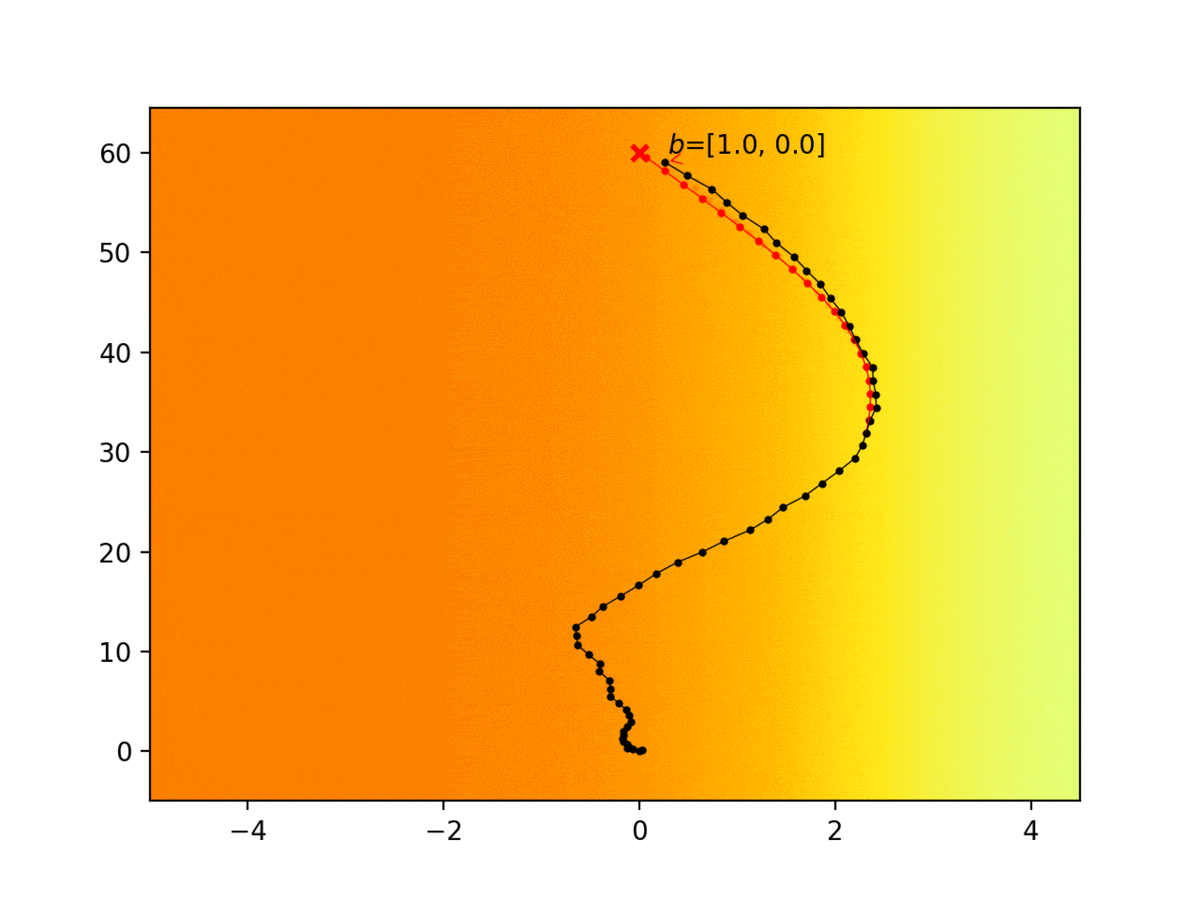
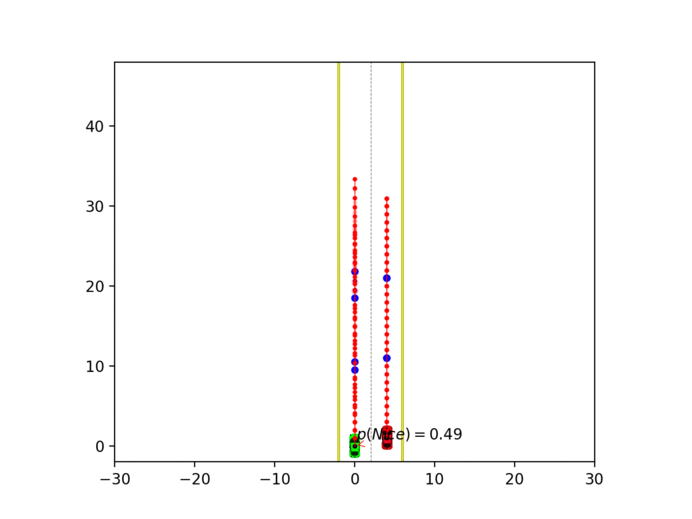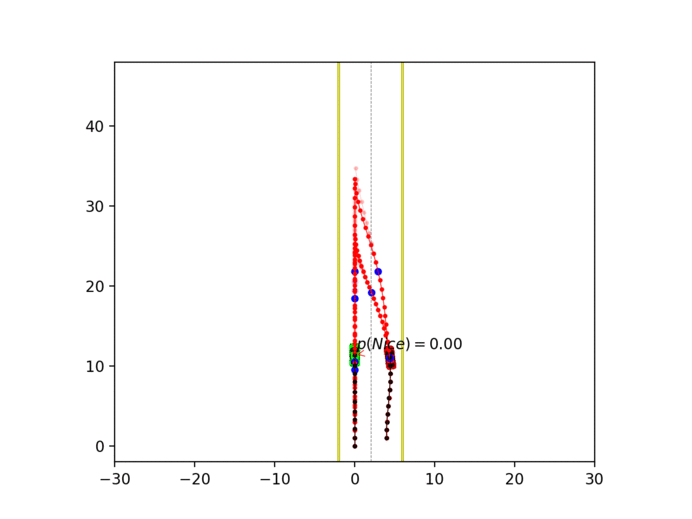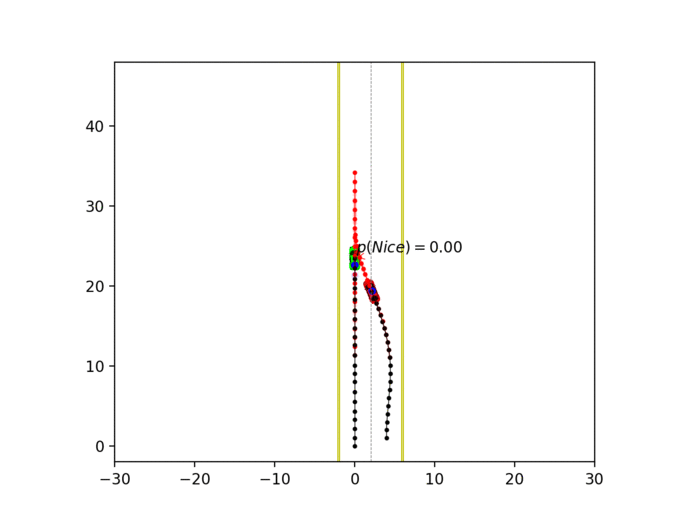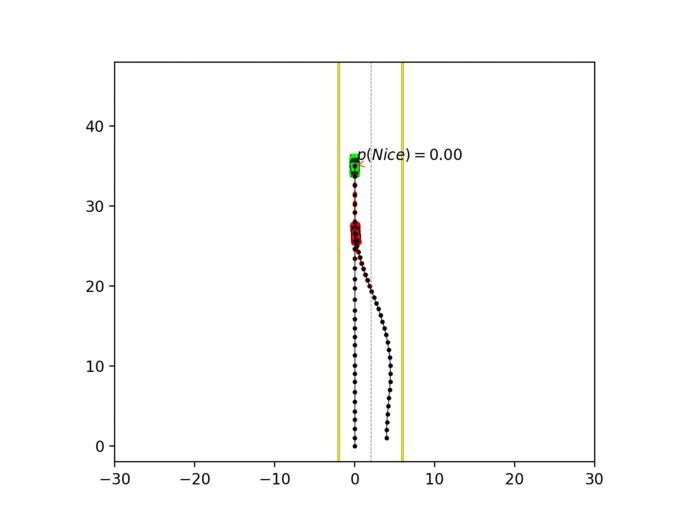
Experiment 1: Planning under cost function uncertainty
PODDP for Left Goal
PODDP for Right Goal
MLDDP for Left Goal
MLDDP for Right Goal
PWDDP for Left Goal
PWDDP for Right Goal
Experiment 2: Planning under dynamical mode uncertainty
PODDP for Smooth Terrain
PODDP for Muddy Terrain
MLDDP for Smooth Terrain
MLDDP for Muddy Terrain
PWDDP for Smooth Terrain
PWDDP for Muddy Terrain
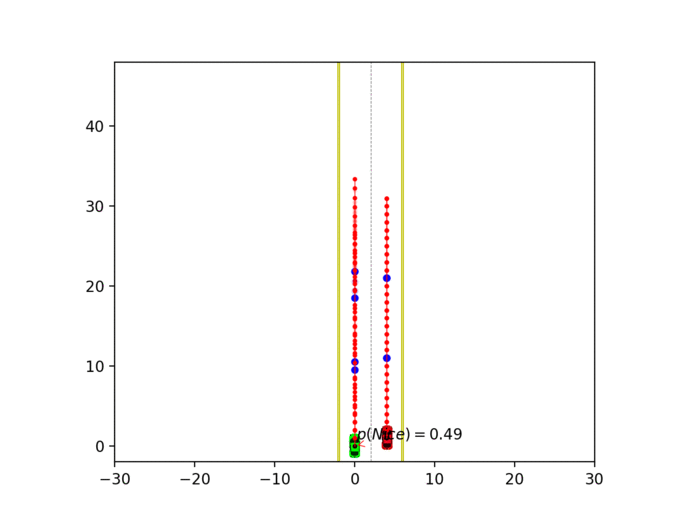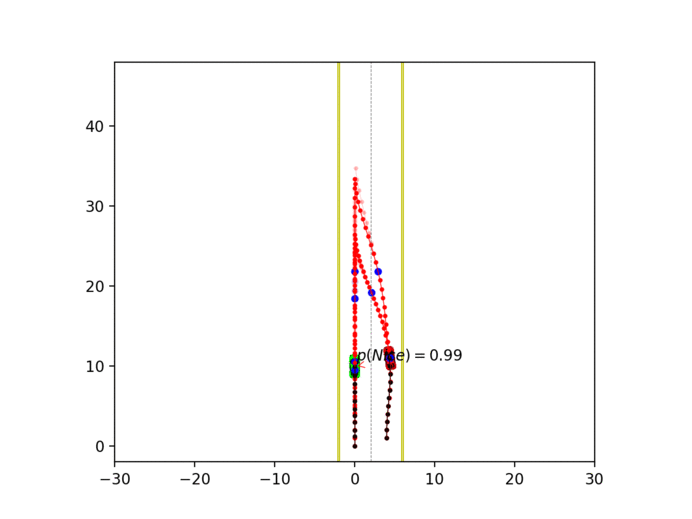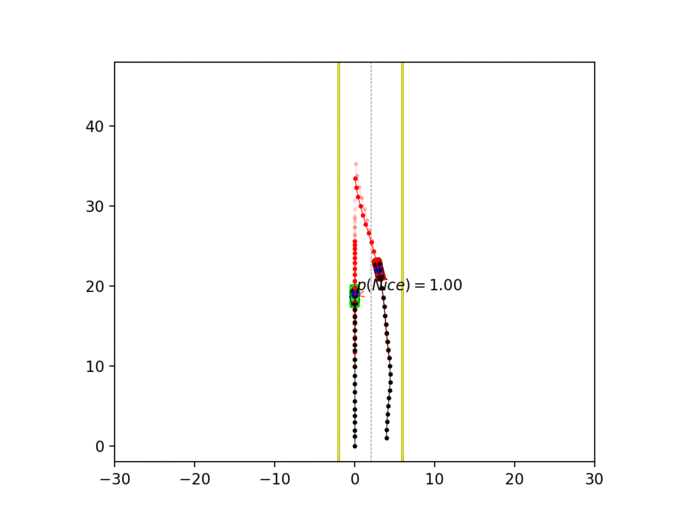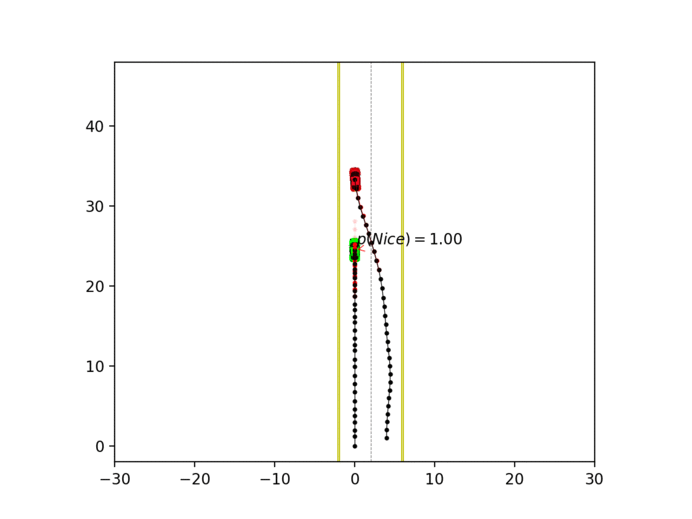
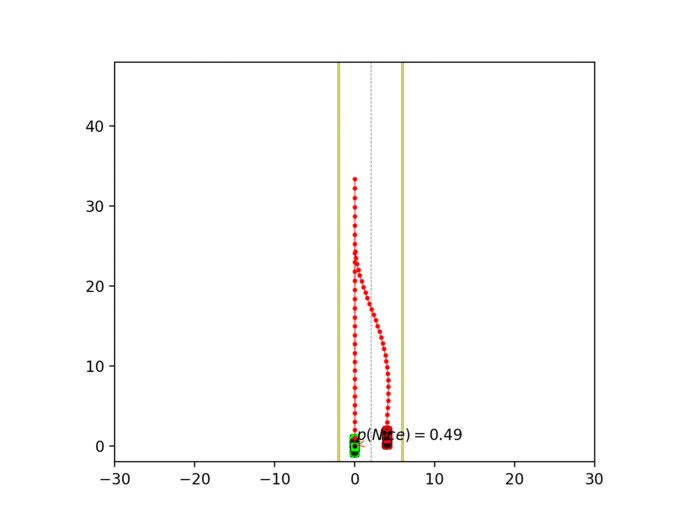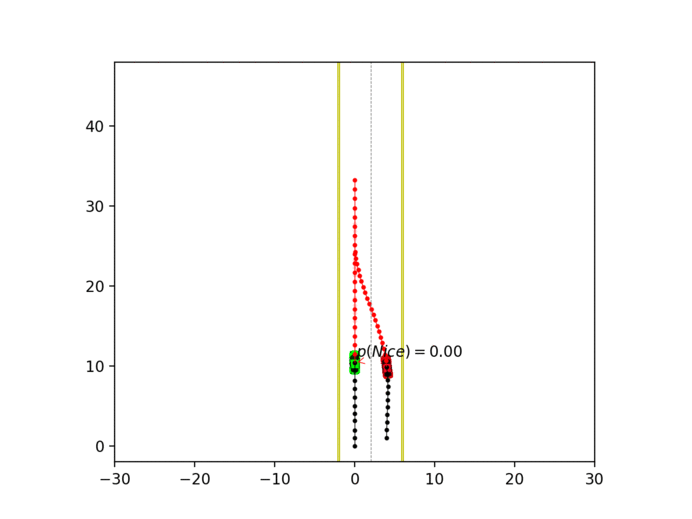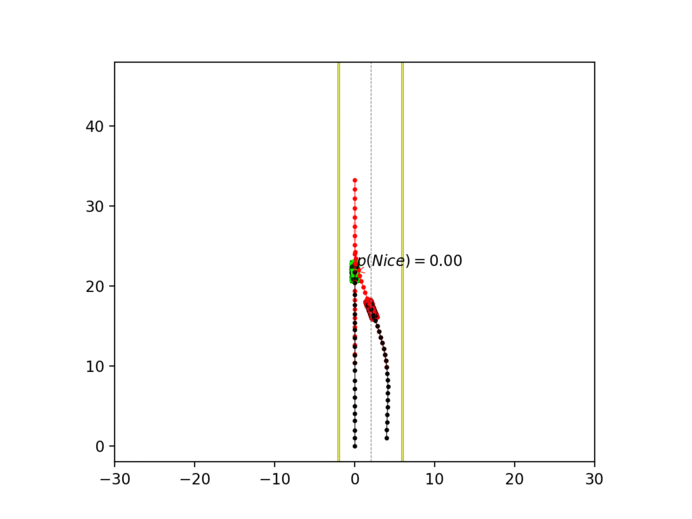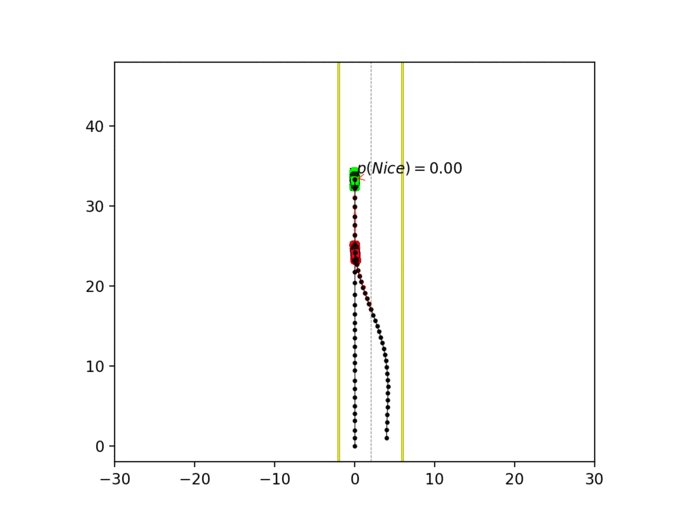
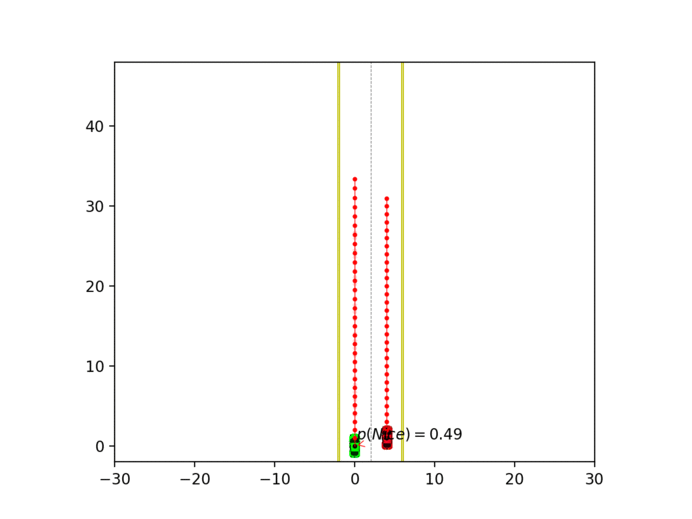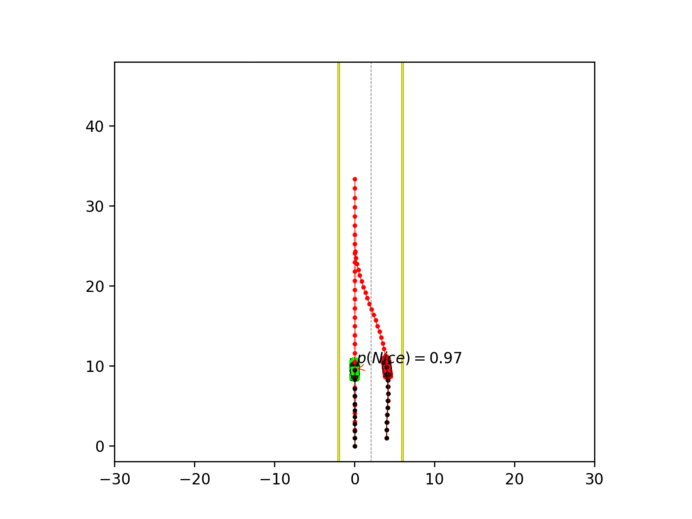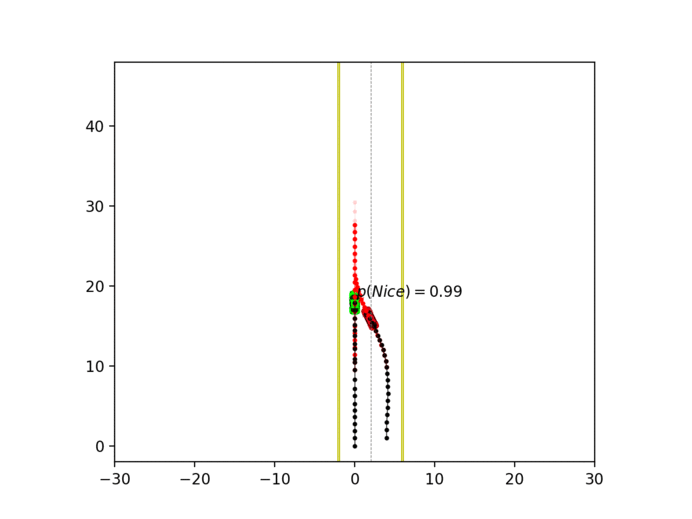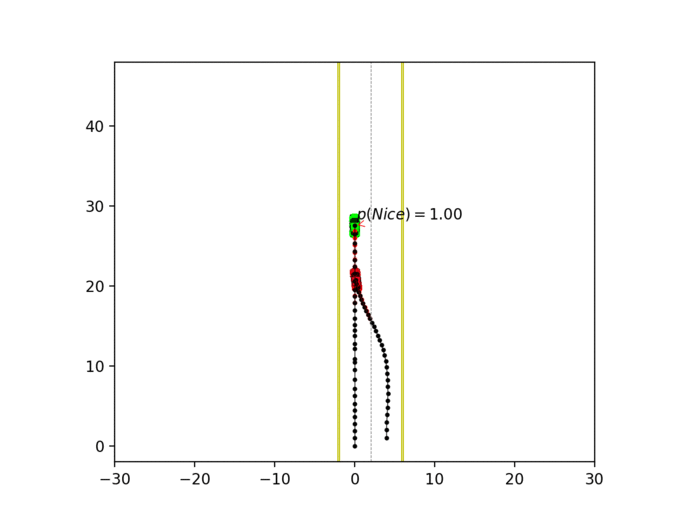
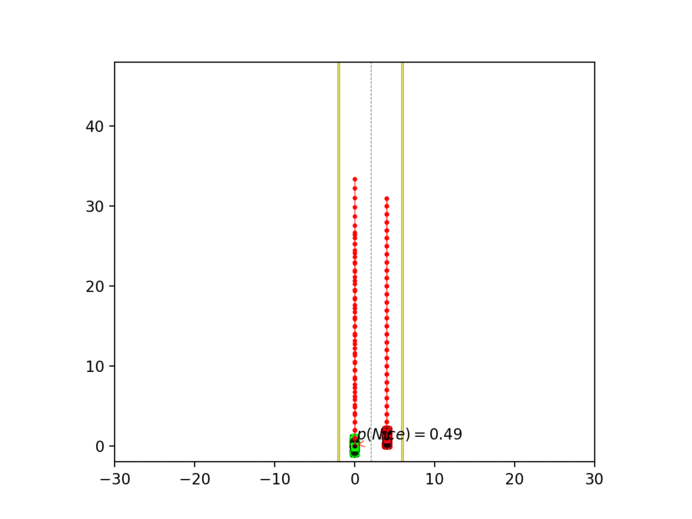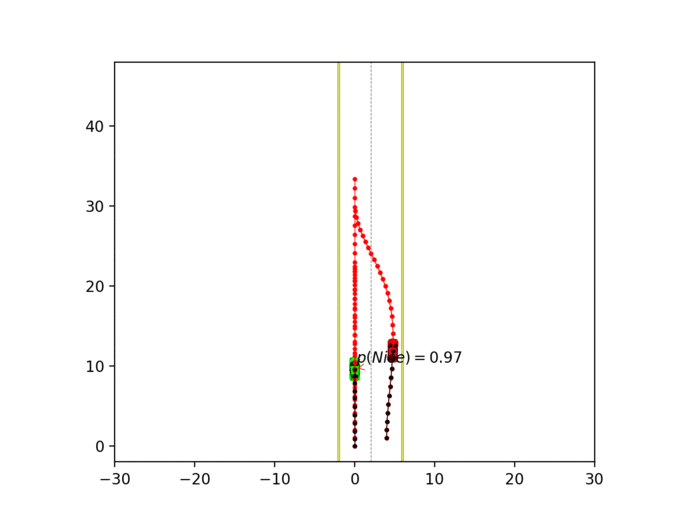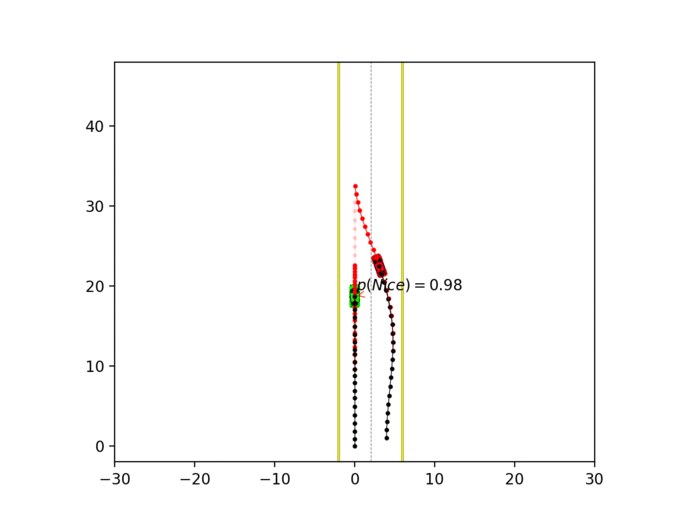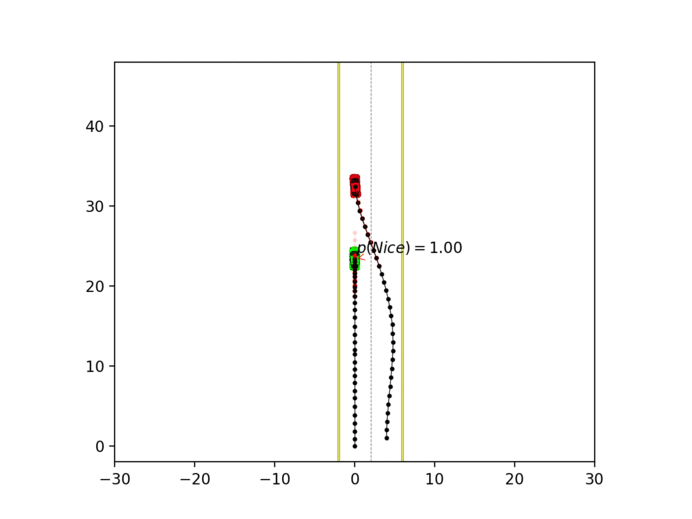
Experiment 3: Latent intention-aware interactive lane changing